ANPR con YOLOV8
ANPR con YOLOV8
Introducción:
YOLO V8 es el último modelo desarrollado por el equipo de Ultralytics. Es un modelo YOLO de última generación que supera a sus predecesores en términos de precisión y eficiencia.
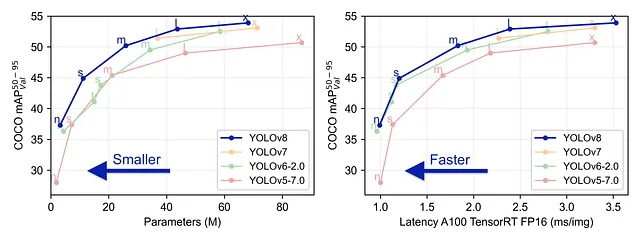
Es fácil de usar y accesible desde la línea de comandos o a través del paquete de Python. Ofrece soporte listo para usar para tareas de detección, clasificación y segmentación de objetos. Recientemente agregó soporte nativo para el seguimiento de objetos, por lo que no tendremos que lidiar con clonar repositorios de algoritmos de seguimiento.
En este artículo, repasaré los pasos para utilizar YOLOV8 y construir una herramienta de reconocimiento automático de matrículas de vehículos (ANPR). Así que empecemos.
Seguimiento de vehículos:
Como mencionamos anteriormente, YOLOV8 tiene seguimiento nativo, por lo que este paso es bastante sencillo. Primero, instale el paquete ultralytics
- El Desvanecimiento Controlado
- Elegir la estrategia de GPU adecuada para tu proyecto de IA
- Comenzando con las Estructuras de Datos en Python en 5 pasos
pip install ultralyticsLuego, debemos leer los fotogramas de video con OpenCV y aplicar el método de seguimiento del modelo con el argumento persist establecido en True para garantizar que los identificadores persistan en el siguiente fotograma. El modelo devuelve las coordenadas para dibujar un cuadro delimitador, junto con el identificador, etiqueta y puntuación.
import cv2from ultralytics import YOLOmodel = YOLO('yolov8n.pt')cap = cv2.VideoCapture("test_vids/vid1.mp4")ret = Truewhile ret: # Leer un fotograma de la cámara ret, frame = cap.read() if ret and frame_nbr % 10 == 0 : results = model.track(frame,persist=True) for result in results[0].boxes.data.tolist(): x1, y1, x2, y2, id, score,label = result # verifique si se cumple el umbral y si el objeto es un automóvil if score > 0.5 and label==2: cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 4) text_x = int(x1) text_y = int(y1) - 10 cv2.putText(frame, str(id), (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]aquí está el resultado en un fotograma:
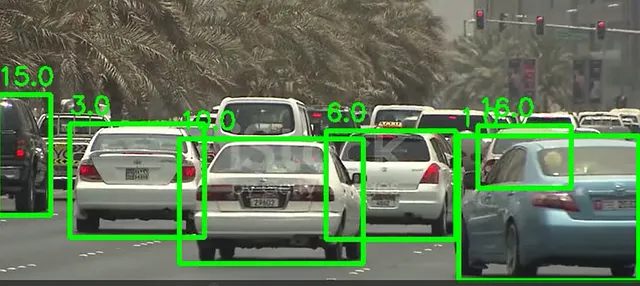
Luego, se utilizan las coordenadas de los cuadros delimitadores para recortar cada automóvil en el fotograma y obtener una imagen.
Reconocimiento de matrículas:
Ahora que tenemos nuestros automóviles, necesitamos detectar las matrículas, para eso, necesitamos entrenar el modelo Yolo. Para eso, utilicé el siguiente conjunto de datos de Kaggle.
Detección de matrículas de automóviles
433 imágenes de matrículas
www.kaggle.com
Sin embargo, las etiquetas en este conjunto de datos están en formato XML de PASCAL VOC:
<annotation> <folder>images</folder> <filename>Cars105.png</filename> <size> <width>400</width> <height>240</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>licence</name> <pose>Unspecified</pose> <truncated>0</truncated> <occluded>0</occluded> <difficult>0</difficult> <bndbox> <xmin>152</xmin> <ymin>147</ymin> <xmax>206</xmax> <ymax>159</ymax> </bndbox> </object></annotation>YOLO necesita las anotaciones de cada imagen en un archivo con el siguiente formato: etiqueta, centro x, centro y, ancho, alto
Este código maneja esa transformación de nuestros datos:
def xml_to_yolo(bbox, w, h): # xmin, ymin, xmax, ymax x_center = ((bbox[2] + bbox[0]) / 2) / w y_center = ((bbox[3] + bbox[1]) / 2) / h width = (bbox[2] - bbox[0]) / w height = (bbox[3] - bbox[1]) / h return [x_center, y_center, width, height]def convert_dataset(): for filename in os.listdir("annotations"): tree = ET.parse(f"annotations/{filename}") root = tree.getroot() name = root.find("filename").text.replace(".png", "") width = int(root.find("size").find("width").text) height = int(root.find("size").find("height").text) for obj in root.findall('object'): box = [] for x in obj.find("bndbox"): box.append(int(x.text)) yolo_box = xml_to_yolo(box, width, height) line = f"0 {yolo_box[0]} {yolo_box[1]} {yolo_box[2]} {yolo_box[3]}" with open(f"train/labels/{name}.txt", "a") as file: # Escribir una línea en el archivo file.write(f"{line}\n")ahora, lo único que queda es configurar nuestro archivo de configuración yaml con las rutas a las carpetas de datos de entrenamiento y validación, luego entrenar el modelo (nota: los nombres de las carpetas dentro de las carpetas de entrenamiento y validación deben ser etiquetas e imágenes). Luego, lo pasamos como argumento a nuestra instancia del modelo y comenzamos el entrenamiento
path: C:/Users/msi/PycharmProjects/ANPR_Yolov8train: trainval: val# Classesnames: 0: matrícula
model = YOLO('yolov8n.yaml')result = model.train(data="config.yaml",device="0",epochs=100,verbose=True,plots=True,save=True)
Ahora que tenemos nuestro modelo de matrícula, simplemente tenemos que cargarlo y usarlo en las imágenes de coches recortadas del video, aplicamos escala de grises en el recorte de la matrícula y usamos easy_ocr para leer su contenido
cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]plates = lp_detector(cropped_img)for plate in plates[0].boxes.data.tolist(): if score > 0.6: x1, y1, x2, y2, score, _ = plate cv2.rectangle(cropped_img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2) lp_crop = cropped_img[int(y1):int(y2), int(x1):int(x2)] lp_crop_gray = cv2.cvtColor(lp_crop, cv2.COLOR_BGR2GRAY) ocr_res = reader.readtext(lp_crop_gray) if not ocr_res: print("No se detectó matrícula") else: entry = {'id': id, 'number': ocr_res[0][1], 'score': ocr_res[0][2]} update_csv(entry) out.write(frame) cv2.imshow('frame', frame) frame_nbr += 1la función update_csv escribirá el ID del coche y el número de matrícula en un archivo CSV. Y eso es el pipeline de ANPR con yolov8
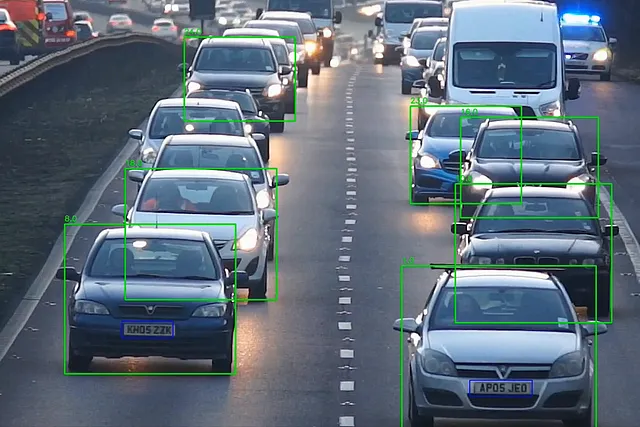
Conclusión:
Como vimos, YOLOV8 simplifica el proceso de construir un pipeline de ANPR ya que ofrece seguimiento nativo y detección de objetos.
este repositorio contiene el proyecto completo donde construí una aplicación de ANPR con streamlit:
GitHub – skandermenzli/ANPR_Yolov8
Contribuye al desarrollo de skandermenzli/ANPR_Yolov8 creando una cuenta en GitHub.
github.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a AnomalyGPT Un nuevo enfoque de IAD basado en Modelos de Visión-Lenguaje de Gran Escala (LVLM) para detectar anomalías industriales
- El icónico escritor de terror Stephen King no teme a la IA
- Predicción de incertidumbre basada en entropía
- Introducción a Semantic Kernel para los entusiastas de Python
- CatBoost Regresión Explícamelo detalladamente
- ¿La implementación del Momentum de Nesterov en PyTorch está equivocada?
- El problema de percepción pública del Aprendizaje Automático