GLIP Introduciendo la Preparación Previa de Lenguaje-Imagen para la Detección de Objetos
GLIP - Pre-Linguistic-Image Preparation for Object Detection
Resumen del artículo: Pre-entrenamiento de lenguaje-imagen fundamentado
Hoy nos sumergiremos en un artículo que se basa en el gran éxito de CLIP en el pre-entrenamiento de lenguaje-imagen y lo extiende a la tarea de detección de objetos: GLIP — Grounded Language-Image Pre-training. Cubriremos los conceptos clave y los hallazgos del artículo y los haremos fáciles de entender al proporcionar un contexto adicional y agregar anotaciones a las imágenes y los resultados de los experimentos. ¡Comencemos!
Artículo: Pre-entrenamiento de lenguaje-imagen fundamentado
Código: https://github.com/microsoft/GLIP
Primera publicación: 7 de diciembre de 2021
- Walmart capacita a sus trabajadores de oficina con una aplicación de IA generativa
- Herramientas principales de privacidad de datos 2023
- Mejores servidores proxy (septiembre de 2023)
Autores: Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, Jianfeng Gao
Categoría: aprendizaje de representaciones, detección de objetos, fundamentos de frases, aprendizaje profundo multimodal, visión por computadora, procesamiento de lenguaje natural, modelos fundamentales
Esquema
- Contexto y antecedentes
- Contribuciones afirmadas
- Método
- Experimentos
- Lecturas y recursos adicionales
Contexto y antecedentes
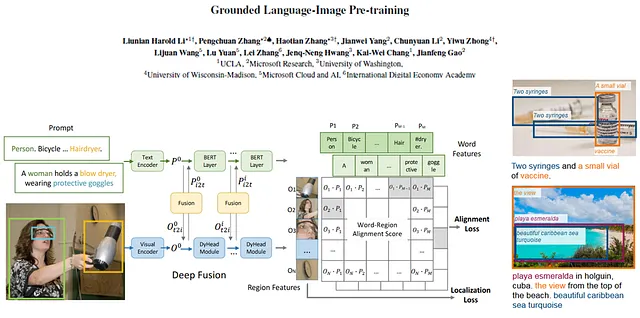
GLIP (Grounded Language-Image Pre-training) es un modelo de lenguaje-imagen multimodal. Al igual que CLIP (Contrastive Language-Image Pre-Training), realiza un pre-entrenamiento contrastivo para aprender representaciones semánticamente ricas y las alinea en sus modalidades. Mientras que CLIP aprende estas representaciones a nivel de imagen, lo que significa que una oración describe toda la imagen, GLIP tiene como objetivo extender este enfoque a representaciones a nivel de objeto, lo que significa que una oración puede corresponder a múltiples objetos dentro de la imagen. La tarea de identificar correspondencias entre tokens individuales en un texto y objetos o regiones en una imagen se denomina fundamentación de frases. De ahí la palabra “fundamentado” en GLIP.
Por lo tanto, GLIP tiene como objetivos:
- Unificar la fundamentación de frases y la detección de objetos para el pre-entrenamiento a gran escala.
- Proporcionar un marco flexible para la detección de objetos sin necesidad de ejemplos, donde flexible significa que no está restringido a un conjunto fijo de clases.
- Construir un modelo pre-entrenado que se transfiera sin problemas a varias tareas y dominios, de manera sin ejemplos o con pocos ejemplos.
¿Qué puedes hacer con un modelo así? Podrías usar frases de texto para encontrar objetos o regiones de interés dentro de una imagen de entrada dada. Y lo mejor de todo: no estás limitado a clases predefinidas.

Puedes procesar aún más estas detecciones (por ejemplo, introduciéndolas en un sistema de seguimiento) o crear un conjunto de datos personalizado con ciertas clases de interés y utilizarlos para entrenar tu propio sistema de detección supervisada. No solo puedes cubrir clases raras o muy específicas, sino que también puedes ahorrar mucho tiempo y dinero en la creación de etiquetas manuales. Como veremos más adelante, los autores de GLIP tuvieron una idea similar para mejorar aún más el rendimiento al introducir un marco de profesor-estudiante.
GLIP ha sido adoptado por muchos otros proyectos y dominios en el aprendizaje profundo. Por ejemplo, GLIGEN (Generación de lenguaje a imagen fundamentada) utiliza GLIP como condición para la generación de imágenes de un modelo de difusión latente para aumentar la controlabilidad. Además, GLIP se ha combinado con otros modelos fundamentales como DINO (Auto-Destilación sin etiquetas) y SAM (Segment Anything) para formar GroundingDINO y Grounded-Segment-Anything respectivamente. GLIPv2 amplía el modelo GLIP inicial con comprensión de visión-lenguaje para mejorar no solo la fundamentación de frases, sino también permitir tareas de respuesta visual a preguntas.
Contribuciones Reclamadas
- Entrenamiento a gran escala para la combinación de localización de frases y detección de objetos
- Proporcionar una visión unificada sobre la detección de objetos y la localización de frases
- Fusión profunda de modalidades cruzadas para aprender representaciones visuales de alta calidad con conocimiento del lenguaje y lograr un rendimiento superior en el aprendizaje por transferencia.
- Presentar que la adaptación de la prompt es más efectiva en la fusión profunda de visión y lenguaje (por ejemplo, GLIP) en comparación con las redes fusionadas superficiales (por ejemplo, CLIP)
Método
Con una idea aproximada de lo que se puede hacer con GLIP, veamos más de cerca los detalles del artículo.
Visión General de la Arquitectura
En un nivel alto, la arquitectura de GLIP es bastante similar a la de CLIP en el sentido de que también consta de un codificador de texto, un codificador de imagen y algún tipo de aprendizaje de contraste sobre la similitud de las características de texto e imagen. La arquitectura de GLIP se muestra en la Fig. 2.
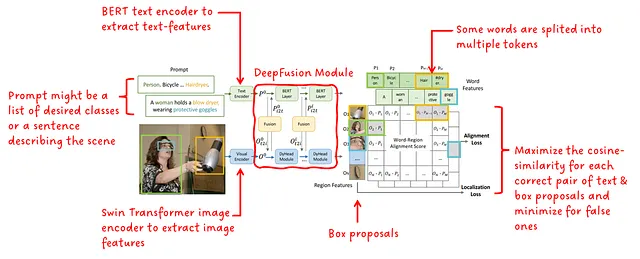
GLIP añade un módulo de fusión profunda con conocimiento de lenguaje-imagen después del codificador de texto e imagen. Este módulo realiza atención cruzada modal y extrae características adicionales. Se calcula una similitud coseno sobre las características de región resultantes y las características de palabras. Durante el entrenamiento, se maximiza la similitud de los pares coincidentes, mientras que se minimiza para los pares incorrectos. A diferencia de CLIP, donde los pares coincidentes se encuentran en la diagonal de la matriz de similitud, en GLIP la coincidencia no se realiza a nivel de oración, sino a nivel de (sub)palabra, lo que generalmente resulta en posiciones fuera de la diagonal.
Localización de Frases Formulada como Problema de Detección de Objetos
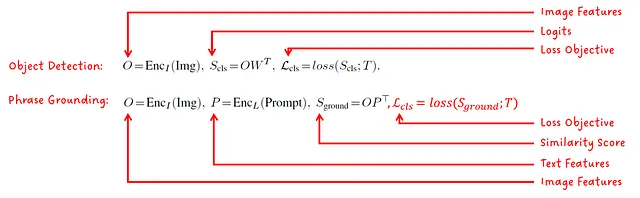
Los autores señalan que el problema de la localización de frases (es decir, asociar palabras con objetos/regiones en una imagen) se puede formular como un objetivo de detección de objetos, donde la pérdida estándar es la siguiente:

La pérdida de localización se refiere a la calidad de la caja delimitadora predicha, que dependiendo del formato, puede ser el tamaño y la ubicación de la caja. La pérdida de clasificación es la parte clave de la unificación. Al calcular los logitos sobre la puntuación de similitud de las características de texto-imagen en lugar de sobre los logitos de un clasificador de imagen, se puede utilizar el mismo objetivo de pérdida para el entrenamiento.
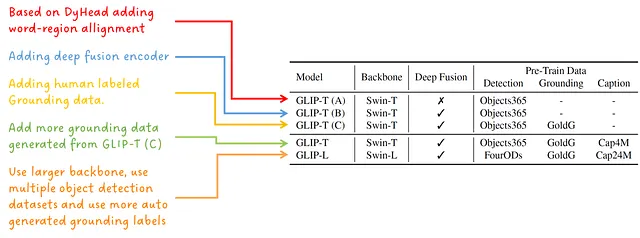
Diferentes Variantes del Modelo
Se entrenaron cinco modelos diferentes para mostrar el efecto de las elecciones de diseño y la escala del modelo de los autores:
Entrenamiento Previo de Maestro-Alumno
Para mejorar el rendimiento de GLIP, los autores entrenan el modelo GLIP-T (C) (ver Fig. 3) con datos anotados por humanos, llamados GoldG, para generar datos de localización a partir de pares de texto-imagen obtenidos de internet. Llaman a este modelo el modelo maestro y posteriormente entrenan un modelo alumno alimentándolo con los datos utilizados para entrenar al maestro más los datos generados por el maestro. Consulta la Fig. 4 para una ilustración.
Nota: Aunque se utilizan los términos maestro y alumno, no es el mismo proceso que la destilación de conocimiento, donde se entrena un modelo alumno más pequeño para que coincida con la salida de un modelo maestro más grande.

Curiosamente, como veremos en los experimentos, el estudiante supera al profesor en muchos (pero no en todos) conjuntos de datos tanto para la detección sin entrenamiento como para la detección con pocos ejemplos. ¿Por qué sucede esto? El artículo plantea la hipótesis de que, aunque el profesor proporciona una predicción con baja confianza (lo llaman “suposición educada”), se convierte en la verdad absoluta (lo llaman “señal supervisada”) en el conjunto de datos generado consumido por el estudiante.
Experimentos
El artículo GLIP presenta varios experimentos y estudios de ablación, principalmente relacionados con:
- Transferencia de Dominio sin Entrenamiento
- Eficiencia de Datos
- Ingeniería de Indicaciones
Tengo algunas dudas sobre algunos de los resultados y la forma en que se presentan, y los señalaré en las anotaciones. No quiero disminuir los logros de GLIP y prefiero verlos con un ojo crítico.
¡Ahora vamos a los detalles!
Transferencia de Dominio sin Entrenamiento
Primero, echaremos un vistazo a los resultados de la transferencia de dominio sin entrenamiento. En esta tarea, el objetivo es analizar qué tan bien funcionan los modelos pre-entrenados de GLIP en un conjunto de datos diferente (es decir, COCO y LVIS) utilizado durante el pre-entrenamiento y compararlo con un modelo de referencia que ha sido entrenado de manera supervisada. Luego, el modelo pre-entrenado de GLIP se ajusta y evalúa aún más en el conjunto de datos bajo prueba.
En la Fig.5 vemos los resultados de la transferencia de dominio sin entrenamiento en COCO. Vemos que todos los modelos de GLIP tienen un mejor rendimiento sin entrenamiento que un Faster RCNN supervisado. También se nos presenta el resultado de que GLIP-L supera al estado del arte previo (en el momento de la publicación del artículo). Vemos que el modelo estudiante más grande GLIP-L supera al modelo profesor GLIP-T (C).
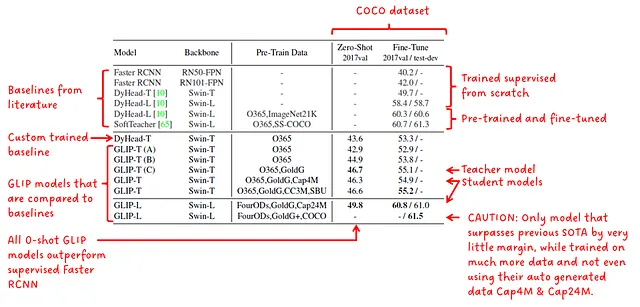
A continuación, lista mis dudas al leer estos resultados y las afirmaciones hechas en el artículo, donde se dice que GLIP-L supera al mejor modelo supervisado SoftTeacher.
- El modelo que tiene mejores métricas que SoftTeacher es GLIP-L, que es mejor por 0.2 puntos. Este pequeño margen podría no ser el resultado del nuevo método de GLIP, sino podría deberse a algunas diferencias en los hiperparámetros de entrenamiento.
- GLIP-L ni siquiera utiliza los datos (Cap4M o Cap24M) generados por el modelo profesor que presentaron como una buena solución.
- GLIP-L ha sido entrenado en un corpus de datos de entrenamiento mucho más grande que SoftTeacher.
En mi opinión, los resultados al comparar los diferentes modelos de GLIP y el modelo DyHead-T que ellos mismos entrenaron son completamente válidos, solo tengo mis dudas en general cuando se comparan diferentes métodos y modelos bajo restricciones no claras o diferentes.
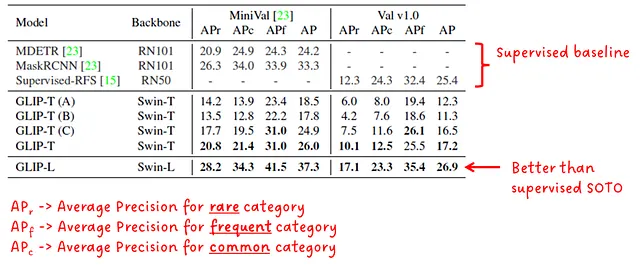
En la Fig.6, vemos el rendimiento de la transferencia de dominio sin entrenamiento en el conjunto de datos de LVIS. Podemos ver que el modelo más grande de GLIP, GLIP-L, supera a todos los demás modelos supervisados presentados.
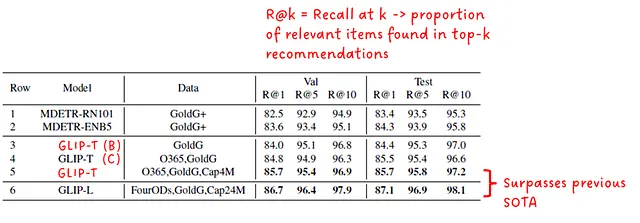
Finalmente, se ha comparado el rendimiento de GLIP en el anclaje de frases en el conjunto de datos de entidades de Flickr30K contra MDETR (ver Fig.7). Ambos modelos estudiantiles, GLIP-T y GLIP-L, superan los baselines de MDETR.
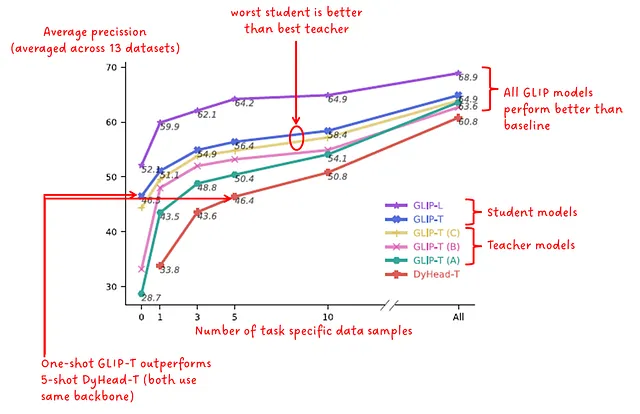
Eficiencia de datos
Otro experimento se preocupa por la eficiencia de datos. Este experimento tiene como objetivo mostrar cómo cambia el rendimiento (en términos de precisión promedio) al ajustar un modelo pre-entrenado en una cierta cantidad de datos específicos de la tarea. En la Fig.8, los modelos se evalúan en 13 conjuntos de datos diferentes y su rendimiento se informa como la precisión promedio promediada en los 13 conjuntos de datos. Se informan resultados para 0-shot, 1-shot, 3-shot, 5-shot, 10-shot y “all”-shot (dudo que sea un término oficial para un ajuste completo, pero supongo que entiendes el punto 😅).
Ingeniería de indicaciones
Similar a CLIP, los autores también informan una correlación entre el rendimiento del modelo y la formulación de la indicación de texto de entrada. Proponen dos técnicas para mejorar el rendimiento de un modelo pre-entrenado, sin necesidad de volver a entrenar los pesos del modelo:
- Ajuste manual de indicaciones
- Ajuste de indicaciones
La idea del ajuste manual de indicaciones es proporcionar un mayor contexto en forma de palabras descriptivas adicionales, ver Fig. 9:
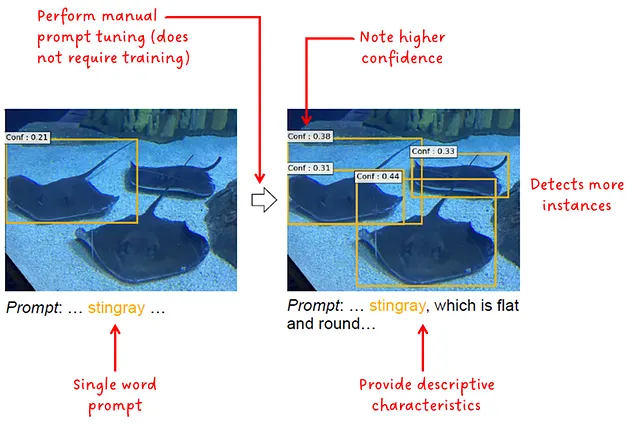
El ajuste manual de indicaciones siempre se puede utilizar para mejorar el rendimiento, lo que significa que no importa si el modelo está completamente ajustado o si se utiliza en un escenario de cero disparos o pocos disparos.
El segundo enfoque, el ajuste de indicaciones, requiere acceso a etiquetas de verdad de referencia de una tarea secundaria y es especialmente adecuado para escenarios donde cada tarea de detección tiene una sola indicación (por ejemplo, “Detectar automóvil”). En ese escenario, esta indicación se traduciría primero en una incrustación de características utilizando el codificador de texto. Luego, el codificador de imágenes y el módulo de fusión profunda se congelan y solo se optimiza la incrustación de entrada utilizando las etiquetas de verdad de referencia. Las incrustaciones optimizadas luego se utilizarían como entrada para el modelo y se podría eliminar el codificador de texto.
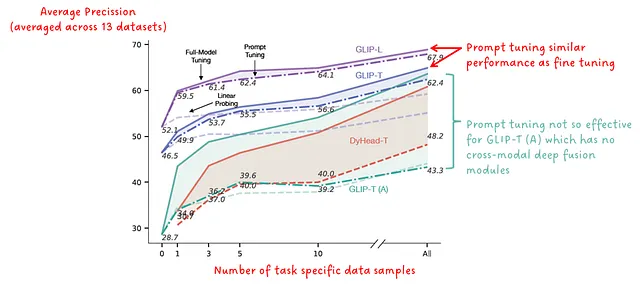
Fig.10 muestra el resultado de este ajuste de indicaciones para varios modelos de GLIP. Cuando se aplica a modelos que tienen un módulo de fusión profunda, el ajuste de indicaciones logra casi el mismo rendimiento que el ajuste de los pesos del modelo.
Más lecturas y recursos
Como se mencionó al principio de este artículo, GLIP ha sido ampliamente adoptado por una gran cantidad de proyectos.
A continuación se muestra una lista de documentos que se basan en GLIP:
- GLIPv2: Unificación de localización y comprensión de visión-idioma
- GLIGEN: Generación de texto a imagen de conjunto abierto
- Grounding DINO: Combinación de DINO con preentrenamiento fundamentado para detección de objetos de conjunto abierto
Aquí tienes una lista de repositorios si quieres profundizar en la implementación de GLIP y otros proyectos interesantes que se basan en GLIP:
- Implementación oficial de GLIP
- Notebook de Python para experimentar con GLIP
- GroundingDINO: combinación de GLIP y DINO
- Grounded-Segment-Anything: combinación de GroundingDINO y SAM
Aquí tienes uno de mis artículos sobre el modelo básico de CLIP, siguiendo el mismo enfoque de resumen que este artículo:
El modelo básico de CLIP
Resumen del artículo: Aprendiendo modelos visuales transferibles a partir de la supervisión del lenguaje natural
towardsdatascience.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- FuncReAct Agente ReAct utilizando llamadas a funciones de OpenAI
- Construyendo un modelo desde cero para generar texto a partir de indicaciones
- Principales tendencias en pruebas de aplicaciones basadas en IA que necesitas conocer
- El viaje de la IA hacia la IA generativa y cómo funciona
- GeForce NOW se vuelve salvaje, con ‘Party Animals’ liderando 24 nuevos juegos en septiembre
- Morphobots para Marte Caltech desarrolla un robot todo terreno como candidato para una misión de la NASA
- Conoce a cinco innovadores en IA generativa en África y Oriente Medio






