NODO Árboles Neuronales Centrados en Tablas
NACET Tree Neural Networks Centered on Tables
Explorando NODE: una arquitectura de Árbol de Decisión Neural para datos tabulares
En los últimos años, el Aprendizaje Automático ha explotado en popularidad, y los modelos de Aprendizaje Profundo basados en redes neuronales han superado a modelos más superficiales como XGBoost [4] en tareas complejas como el procesamiento de imágenes y texto. Sin embargo, los modelos profundos a menudo son menos efectivos que estos modelos superficiales en cuanto a datos tabulares, y no existe un enfoque universal de aprendizaje profundo que consistentemente supere a los árboles de aumento de gradiente.
Para abordar esta brecha, los investigadores de la empresa rusa de servicios de internet Yandex han propuesto una nueva arquitectura: Neural Oblivious Decision Ensembles (NODE) [1]. Esta red utiliza árboles de decisión neuronales ligeros e interpretables e los integra dentro de un marco de red neuronal. Esto permite que el modelo capture interacciones y dependencias complejas en datos tabulares mientras mantiene la interpretabilidad.
En este artículo, mi objetivo es explicar cómo funciona NODE y los diversos atributos que lo convierten en un modelo de predicción sólido pero interpretable. Como siempre, animo a todos a leer el artículo original. Si quieres utilizar NODE, por favor visita el repositorio de GitHub del modelo.
Este artículo es parte de una serie sobre Árboles de Decisión Neuronales, arquitecturas altamente explicables que proporcionan un poder predictivo equivalente a las redes neuronales profundas tradicionales.
- ¿Pueden los modelos de lenguaje pequeños ofrecer un alto rendimiento? Conoce a StableLM un modelo de lenguaje de código abierto que puede generar texto y código, brindando un alto rendimiento con un entrenamiento adecuado.
- ¿Qué son los Modelos de Lenguaje Grandes (LLMs)? Aplicaciones y Tipos de LLMs
- ¿Qué sucede si ejecutas un modelo Transformer con una red neuronal óptica?

Nakul Upadhya
Árboles de Decisión Suaves/Neuronales
Ver lista de 2 historias

Estructura del Árbol de Decisión NODE
Árboles de Decisión Neuronales
Este artículo asume que tienes cierta familiaridad con los Árboles de Decisión Neuronales. Si no la tienes, te animo a que leas mi artículo anterior sobre ellos para una explicación más detallada. Sin embargo, en resumen: los árboles de decisión neuronales son árboles de decisión que son a la vez suaves y oblicuos.
Un árbol oblicuo es aquel en el que se utilizan múltiples variables para tomar decisiones en cada nodo (generalmente dispuestas en una combinación lineal). Por ejemplo, para predecir un accidente de coche, un árbol ortogonal puede producir una decisión de ramificación utilizando la regla “velocidad_del_coche – límite_de_velocidad <10". Esto difiere de los árboles "ortogonales" como CART (el árbol de decisión básico), que solo utiliza una variable en cualquier nodo dado y necesitará más nodos para aproximar el mismo límite de decisión.
Un árbol suave es aquel en el que todas las decisiones de ramificación son probabilísticas, y los cálculos en cada nodo definen la probabilidad de ir a una rama particular. Esto es diferente de los árboles de decisión regulares y “duros” como CART, donde cada decisión de ramificación es determinista.
Dado que el árbol no restringe la cantidad de variables utilizadas en cada nodo, y las decisiones de ramificación son continuas, todo el árbol es diferenciable. Dado que todo el árbol es diferenciable, se puede integrar en cualquier marco de red neuronal como Pytorch o Tensorflow y entrenarlo utilizando optimizadores neuronales tradicionales (por ejemplo, Descenso de Gradiente Estocástico y Adam).
Árboles NODE
Los árboles de decisión que utiliza NODE son ligeramente diferentes de los árboles neuronales tradicionales. Veamos todas las diferencias.
Naturaleza Oblivious
El primer cambio significativo es el hecho de que los árboles son Oblivious. Esto significa que el árbol utiliza los mismos pesos de división y umbrales para todos los nodos internos de la misma profundidad. Como resultado, los Árboles de Decisión Oblivious (ODTs) se pueden representar como una tabla de decisiones con 2^ d entradas ( d es la profundidad). Una ventaja es que los ODTs son más interpretables que los árboles de decisión tradicionales, ya que hay menos decisiones que analizar, lo que hace que el camino de decisión sea más fácil de visualizar y comprender. Sin embargo, los ODT son aprendices significativamente más débiles en comparación con los árboles de decisión tradicionales (nuevamente debido a la naturaleza restrictiva de las funciones de división).
Entonces, si nuestro objetivo es el rendimiento, ¿por qué usaríamos ODTs? Como mostraron los desarrolladores de CATBoost [2], los ODT funcionan increíblemente bien cuando se ensamblan juntos y son menos propensos al sobreajuste de los datos. Además, la inferencia de los ODT es extremadamente eficiente, ya que las divisiones se pueden calcular en paralelo para encontrar rápidamente la entrada adecuada en la tabla.
Entmax para la selección de características y ramificación
La segunda mejora de NODE sobre el árbol de decisión neuronal tradicional es el uso de alpha-entmax [3] en su arquitectura en lugar de sigmoid. Alpha-entmax es una versión generalizada de softmax capaz de producir distribuciones dispersas donde la mayoría de los resultados son iguales a cero. Esta dispersión está controlada por un parámetro (alpha, de ahí el nombre) donde cuanto mayor sea el alpha, más dispersa será la distribución.
![Figura de Peters et al. 2019 [3]](https://miro.medium.com/v2/resize:fit:640/format:webp/0*F_Ar1Nyc6BxnVXsP.png)
Esta transformación se utiliza en dos lugares clave. El primer uso es en la selección de características dispersas. NODE incluye una matriz de pesos de selección de características entrenable F (de tamaño d x n donde n es el número de características y d es la profundidad del árbol) que se pasa a través de la transformación entmax. Dado que la mayoría de las entradas de la transformación entmax son iguales a cero, esto resulta naturalmente en un pequeño número de características utilizadas en cada nodo de decisión.
![Función de ramificación (Figura de Popov et al. 2019 [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/1*hCu6EpU9LVxeHL2cLN6UVQ.png)
Además de la selección de características, entmax también se utiliza para las probabilidades de ramificación. Esto se hace pasando el resultado de la función de ramificación, restando un umbral aprendido y escalándolo adecuadamente. Este valor se concatena con 0 y se pasa a la función entmax para crear una distribución de probabilidad de 2 clases, que es exactamente lo que necesitamos para la ramificación.
![Ecuación de ramificación de [1]. b_i es el umbral de ramificación tau_i es un valor aprendido para escalar los datos (Figura del autor)](https://miro.medium.com/v2/resize:fit:640/format:webp/0*bWVGEq4eXFEVWwa3.png)
Usando esto, podemos definir un tensor de “elección” C calculando el producto externo de todas las distribuciones de ramificación c. Esto luego se puede multiplicar por los valores en la hoja para crear el resultado de la red.
Ensamblado
Como sugiere el nombre, estos árboles de decisión neuronales sin memoria se ensamblan juntos. Una capa NODE se define como una concatenación de m árboles individuales, cada uno con sus propias decisiones de ramificación y valores de hoja. Como se mencionó antes, este ensamblado sinérgico con la naturaleza olvidadiza de los árboles individuales ayuda a aumentar la precisión con una reducida probabilidad de sobreajuste.
NODE Multicapa
NODE es una arquitectura flexible que se puede entrenar sola (resultando en un solo ensamblado de árboles de decisión) o con una estructura multicapa compleja donde cada conjunto de ensamblados toma como entrada la capa anterior.
![Arquitectura NODE multicapa (Figura de Popov et al. 2019 [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/1*WyQVp9Dg6JygVcKTPtYtAg.png)
La arquitectura multicapa de NODE sigue de cerca la popular arquitectura DenseNet. Cada capa NODE contiene varios árboles cuyas salidas se concatenan y se utilizan como entradas para las capas posteriores. La salida final se obtiene promediando la salida de todos los árboles de todas las capas. Dado que cada capa se basa en cadenas de todas las predicciones anteriores, la red puede capturar dependencias complejas.
Rendimiento experimental
Para probar su arquitectura, Popov et al. (2019) compararon NODE con CatBoost [2], XGBoost[4], una red neuronal completamente conectada, mGBDT [5] y DeepForest [6]. Su metodología involucró probar los modelos en seis conjuntos de datos diferentes. Específicamente, hicieron una comparación utilizando los parámetros predeterminados de cada modelo y otra comparación donde cada modelo tenía hiperparámetros ajustados.
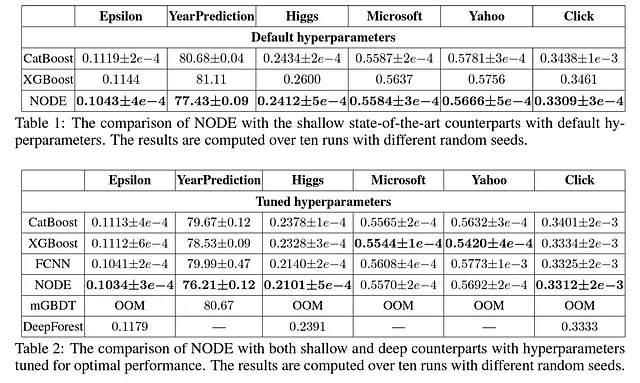
Los resultados experimentales para NODE son extremadamente alentadores. Por un lado, la arquitectura de NODE supera a todos los demás modelos con los parámetros predeterminados. Incluso con parámetros ajustados, NODE supera a la mayoría de los otros modelos en 4 de los 6 conjuntos de datos seleccionados.
Conclusión
Al incorporar las ventajas de los árboles de decisión en la arquitectura de la red neural, NODE abre nuevas posibilidades para aplicaciones de aprendizaje profundo en dominios donde los datos estructurados en forma de tabla son frecuentes, como finanzas, atención médica y análisis de clientes.
Esto no quiere decir que NODE sea perfecto, sin embargo. Por un lado, la combinación de la arquitectura significa que muchas de las ganancias de interpretabilidad local al utilizar árboles de decisión neuronales se desechan, y solo se pueden obtener importancias de características globales del modelo. Sin embargo, esta arquitectura proporciona los cimientos para mejorar la interpretabilidad neuronal, y se ha propuesto un modelo de seguimiento (NODE-GAM [7]) para cerrar la brecha de interpretabilidad.
Además, aunque NODE supera a muchos modelos superficiales, mi experiencia al usarlo ha indicado que tarda más en entrenar, incluso cuando se utilizan unidades de procesamiento gráfico (una conclusión respaldada por los resultados experimentales proporcionados por los autores del artículo).
En general, este enfoque es extremadamente prometedor y planeo usarlo activamente como componente de los modelos de aprendizaje profundo que desarrolle en el futuro.
Recursos y Referencias
- Artículo de NODE: https://arxiv.org/abs/1909.06312
- Código de NODE: https://github.com/Qwicen/node
- NODE también se puede encontrar en el paquete Pytorch Tabular: https://github.com/manujosephv/pytorch_tabular
- Si estás interesado en el aprendizaje automático interpretable o la predicción de series de tiempo, considera seguirme: https://medium.com/@upadhyan .
- Consulta mis otros artículos sobre árboles de decisión neuronales: https://medium.com/@upadhyan/list/3b4a9cb97b84
Referencias
[1] Popov, S., Morozov, S., & Babenko, A. (2019). Neural oblivious decision ensembles for deep learning on tabular data. Octava Conferencia Internacional sobre Representaciones de Aprendizaje.
[2] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. (2018). CatBoost: boosting imparcial con características categóricas. Avances en sistemas de información neural , 31 .
[3] Peters, B., Niculae, V., & Martins, A. (2019). Modelos secuenciales escasos. En Actas de la 57ª Reunión Anual de la Asociación de Lingüística Computacional (pp. 1504–1519). Asociación de Lingüística Computacional.
[4] Chen, T., & Guestrin, C. (2016, agosto). Xgboost: un sistema de refuerzo de árbol escalable. En Actas de la 22ª Conferencia Internacional de la ACM SIGKDD sobre Descubrimiento de Conocimiento y Minería de Datos (pp. 785–794).
[5] Feng, J., Yu, Y., & Zhou, Z. H. (2018). Árboles de decisión de refuerzo multicapa. Avances en sistemas de información neural , 31 .
[6] Zhou, Z. H., & Feng, J. (2019). Bosque profundo. Revisión científica nacional , 6 (1), 74-86.
[7] Chang, C.H., Caruana, R., & Goldenberg, A. (2022). NODE-GAM: Modelo aditivo generalizado neuronal para aprendizaje profundo interpretable. En Conferencia Internacional sobre Representaciones de Aprendizaje.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Esta Herramienta de IA Explica Cómo la IA ‘Ve’ Imágenes y por qué Puede Equivocarse al Confundir un Astronauta con una Pala.
- Google AI presenta los complementos de difusión de MediaPipe que permiten la generación controlable de texto a imagen en el dispositivo.
- Salesforce presenta XGen-7B Un nuevo 7B LLM entrenado en secuencias de hasta 8K de longitud para 1.5T Tokens.
- ¿Pueden los LLMs generar pruebas matemáticas que puedan ser rigurosamente verificadas? Conoce LeanDojo un espacio de juego de inteligencia artificial de código abierto con herramientas, puntos de referencia y modelos para que los modelos de lenguaje grandes demuestren teoremas formales en el asistente de pruebas Lean.
- Contextual AI presenta LENS un marco de inteligencia artificial para modelos de lenguaje con visión aumentada que supera a Flamingo en un 9% (56->65%) en VQAv2.
- Unity anuncia el lanzamiento de Muse una plataforma de juegos de texto a video que te permite crear texturas, sprites y animaciones con lenguaje natural.
- Conoce a FastSAM La solución revolucionaria en tiempo real que logra una segmentación de alto rendimiento con una carga computacional mínima.