Haciendo Predicciones Una Guía para Principiantes sobre Regresión Lineal en Python.
Guía de Regresión Lineal en Python para Principiantes Predicciones.
Aprende todo sobre el algoritmo de Machine Learning más popular, Regresión Lineal, con su intuición matemática e implementación en Python.

La Regresión Lineal es el algoritmo de aprendizaje automático más popular y el primero que aprende un científico de datos al comenzar su carrera en ciencia de datos. Es el algoritmo de aprendizaje supervisado más importante, ya que establece los bloques de construcción para todos los demás algoritmos avanzados de aprendizaje automático. Es por eso que necesitamos aprender y comprender este algoritmo de manera muy clara.
En este artículo, cubriremos la Regresión Lineal desde cero, su intuición matemática y geométrica, y su implementación en Python. El único requisito previo es su disposición para aprender y el conocimiento básico de la sintaxis de Python. Empecemos.
- El Maestro Gamer de la IA de DeepMind Aprende 26 juegos en 2 horas.
- La amistad con la modalidad única ha terminado, ahora la multi-modalidad es mi mejor amiga CoDi es un modelo de IA que puede lograr la generación de cualquier tipo a cualquier tipo a través de la difusión componible.
- CEO de NVIDIA Los creadores serán potenciados por la IA generativa.
¿Qué es la Regresión Lineal?
La Regresión Lineal es un algoritmo de aprendizaje automático supervisado que se utiliza para resolver problemas de regresión. Los modelos de regresión se utilizan para predecir una salida continua basada en otros factores. Por ejemplo, predecir el precio de las acciones de una organización el próximo mes considerando los margenes de ganancia, la capitalización total del mercado, el crecimiento anual, etc. La Regresión Lineal también se puede utilizar en aplicaciones como la predicción del clima, los precios de las acciones, los objetivos de ventas, etc.
Como su nombre sugiere, la Regresión Lineal desarrolla una relación lineal entre dos variables. El algoritmo encuentra la mejor línea recta ( y=mx+c ) que puede predecir la variable dependiente (y) en función de las variables independientes (x). La variable predicha se llama variable dependiente o variable objetivo, y las variables utilizadas para predecir se llaman variables independientes o características. Si solo se utiliza una variable independiente, se llama Regresión Lineal Univariable. De lo contrario, se llama Regresión Lineal Multivariable.
Para simplificar este artículo, solo tomaremos una variable independiente (x) para que podamos visualizarla fácilmente en un plano 2D. En la siguiente sección, discutiremos su intuición matemática.
Intuición Matemática
Ahora entenderemos la geometría y las matemáticas de la Regresión Lineal. Supongamos que tenemos un conjunto de pares de valores X e Y de muestra,
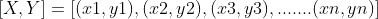
Debemos usar estos valores para aprender una función para que si le damos un valor desconocido (x), pueda predecir un valor (y) basado en el aprendizaje. En regresión, se pueden utilizar muchas funciones para la predicción, pero la función lineal es la más simple de todas.
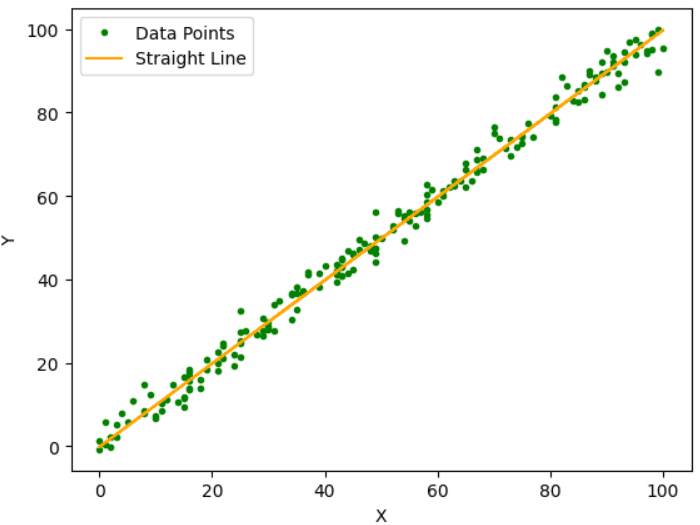
El objetivo principal de este algoritmo es encontrar la mejor línea de ajuste entre estos puntos de datos, como se indica en la figura anterior, que da el menor error residual. El error residual es la diferencia entre el valor predicho y el valor actual.
Supuestos para la Regresión Lineal
Antes de avanzar, debemos discutir algunos supuestos de la Regresión Lineal que debemos tener en cuenta para obtener predicciones precisas.
- Linealidad: La linealidad significa que las variables independientes y dependientes deben seguir una relación lineal. De lo contrario, será difícil obtener una línea recta. Además, los puntos de datos deben ser independientes entre sí, es decir, los datos de una observación no dependen de los datos de otra observación.
- Homocedasticidad: Indica que la varianza de los errores residuales debe ser constante. Significa que la varianza de los términos de error debe ser constante y no cambia incluso si los valores de la variable independiente cambian. Además, los errores en el modelo deben seguir una distribución normal.
- No Multicolinealidad: La multicolinealidad significa que hay una correlación entre las variables independientes. Por lo tanto, en la Regresión Lineal, las variables independientes no deben estar correlacionadas entre sí.
Función de Hipótesis
Supondremos que existirá una relación lineal entre nuestra variable dependiente(Y) y la variable independiente(X). Podemos representar la relación lineal de la siguiente manera.

Podemos observar que la línea recta depende de los parámetros Θ0 y Θ1. Entonces, para obtener la mejor línea de ajuste, necesitamos ajustar o ajustar estos parámetros. También se llaman los pesos del modelo. Y para calcular estos valores, usaremos la función de pérdida, también conocida como función de costo. Calcula el Error Cuadrático Medio entre los valores predichos y reales. Nuestro objetivo es minimizar esta función de costo. Los valores de Θ0 y Θ1, en los que se minimiza la función de costo, formarán nuestra mejor línea de ajuste. La función de costo se representa por (J)
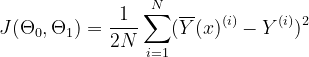
Donde,
N es el número total de muestras
Se escoge la función de error cuadrático para manejar los valores negativos (es decir, si el valor predicho es menor que el valor real). Además, la función se divide por 2 para facilitar el proceso de diferenciación.
Optimizador (Descenso de Gradiente)
El optimizador es un algoritmo que minimiza el MSE actualizando iterativamente los atributos del modelo como los pesos o la tasa de aprendizaje para lograr la mejor línea de ajuste. En la regresión lineal, se utiliza el algoritmo de Descenso de Gradiente para minimizar la función de costo actualizando los valores de Θ0 y Θ1.
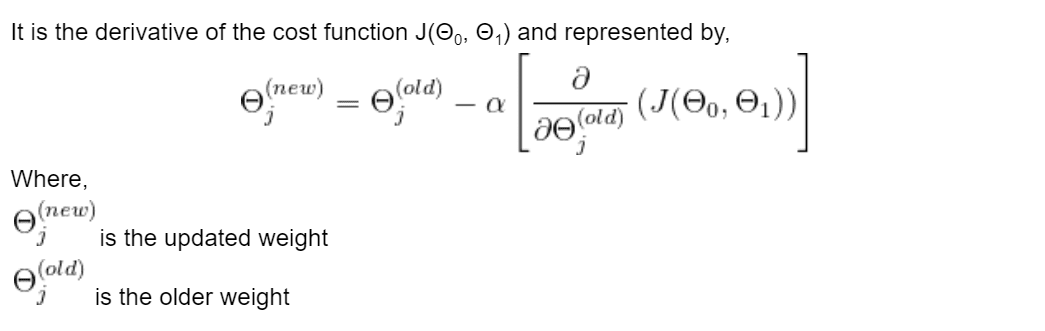
es un hiperparámetro que se llama tasa de aprendizaje. Determina cuánto se ajustan nuestros pesos con respecto a la pérdida de gradiente. El valor de la tasa de aprendizaje debe ser óptimo, ni demasiado alto ni demasiado bajo. Si es demasiado alto, es difícil que el modelo converja al mínimo global, y si es demasiado pequeño, tarda más en converger.
Graficaremos una gráfica entre la función de costo y los pesos para encontrar los valores óptimos de Θ0 y Θ1.
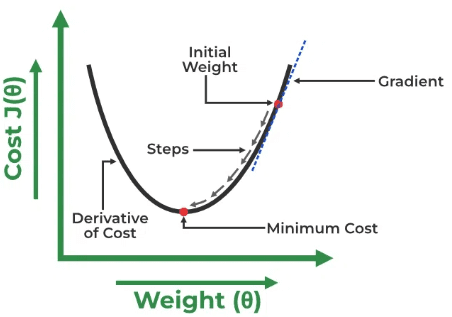
Inicialmente, asignaremos valores aleatorios a Θ0 y Θ1, luego calcularemos la función de costo y el gradiente. Para un gradiente negativo (una derivada de la función de costo), necesitamos movernos en la dirección de aumento de Θ1 para alcanzar el mínimo. Y para un gradiente positivo, debemos retroceder para alcanzar el mínimo global. Nuestro objetivo es encontrar un punto en el que el gradiente casi sea cero. En este punto, el valor de la función de costo es mínimo.
En este punto, el valor de la función de costo es mínimo.
Hasta ahora, ha entendido el funcionamiento y las matemáticas de la regresión lineal. La siguiente sección verá cómo implementarlo desde cero usando Python en un conjunto de datos de muestra.
Implementación de la regresión lineal en Python
En esta sección, aprenderemos cómo implementar el algoritmo de regresión lineal desde cero solo usando bibliotecas fundamentales como Numpy, Pandas y Matplotlib. Implementaremos la regresión lineal univariante, que contiene solo una variable dependiente y una independiente.
El conjunto de datos que utilizaremos contiene alrededor de 700 pares de (X, Y) en los que X es la variable independiente e Y es la variable dependiente. Ashish Jangra contribuye con este conjunto de datos, y puede descargarlo desde aquí.
Importación de bibliotecas
# Importar bibliotecas necesarias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.axes as ax
from IPython.display import clear_outputPandas lee el archivo CSV y obtiene el dataframe, mientras que Numpy realiza operaciones matemáticas y estadísticas básicas. Matplotlib es responsable de trazar gráficos y curvas.
Cargando el conjunto de datos
# Enlace del conjunto de datos:
# https://github.com/AshishJangra27/Machine-Learning-with-Python-GFG/tree/main/Linear%20Regression
df = pd.read_csv("lr_dataset.csv")
df.head()
# Eliminar valores nulos
df = df.dropna()
# División de entrenamiento-prueba
N = len(df)
x_train, y_train = np.array(df.X[0:500]).reshape(500, 1), np.array(df.Y[0:500]).reshape(
500, 1
)
x_test, y_test = np.array(df.X[500:N]).reshape(N - 500, 1), np.array(
df.Y[500:N]
).reshape(N - 500, 1)Primero, obtendremos el dataframe df y luego eliminaremos los valores nulos. Después de eso, dividiremos los datos en entrenamiento y prueba x_train, y_train, x_test y y_test.
Construyendo el modelo
class LinearRegression:
def __init__(self):
self.Q0 = np.random.uniform(0, 1) * -1 # Intercepción
self.Q1 = np.random.uniform(0, 1) * -1 # Coeficiente de X
self.losses = [] # Almacenando la pérdida de cada iteración
def forward_propogation(self, training_input):
predicted_values = np.multiply(self.Q1, training_input) + self.Q0 # y = mx + c
return predicted_values
def cost(self, predictions, training_output):
return np.mean((predictions - training_output) ** 2) # Calculando la función de costo
def finding_derivatives(self, cost, predictions, training_input, training_output):
diff = predictions - training_output
dQ0 = np.mean(diff) # d(J(Q0, Q1))/d(Q0)
dQ1 = np.mean(np.multiply(diff, training_input)) # d(J(Q0, Q1))/d(Q1)
return dQ0, dQ1
def train(self, x_train, y_train, lr, itrs):
for i in range(itrs):
# Encontrando los valores predichos (Usando la ecuación lineal y=mx+c)
predicted_values = self.forward_propogation(x_train)
# Calculando la pérdida
loss = self.cost(predicted_values, y_train)
self.losses.append(loss)
# Propagación hacia atrás (Encontrando las derivadas de los pesos)
dQ0, dQ1 = self.finding_derivatives(
loss, predicted_values, x_train, y_train
)
# Actualizando los pesos
self.Q0 = self.Q0 - lr * (dQ0)
self.Q1 = self.Q1 - lr * (dQ1)
# Actualizará dinámicamente la trama de la línea recta
line = self.Q0 + x_train * self.Q1
clear_output(wait=True)
plt.plot(x_train, y_train, "+", label="Valores reales")
plt.plot(x_train, line, label="Ecuación lineal")
plt.xlabel("X de entrenamiento")
plt.ylabel("Y de entrenamiento")
plt.legend()
plt.show()
return (
self.Q0,
self.Q1,
self.losses,
) # Devolver los pesos finales del modelo y las pérdidasHemos creado una clase llamada LinearRegression() en la cual todas las funciones necesarias están construidas.
__init__: Es un constructor y inicializará los pesos con valores aleatorios cuando se cree el objeto de esta clase.
forward_propagation(): Esta función encontrará la salida predicha utilizando la ecuación de la línea recta.
cost(): Esto calculará el error residual asociado con los valores predichos.
finding_derivatives(): Esta función calcula la derivada de los pesos, que posteriormente se pueden usar para actualizar los pesos para obtener errores mínimos.
train(): Esta función tomará la entrada de los datos de entrenamiento, la tasa de aprendizaje y el número total de iteraciones. Actualizará los pesos utilizando la propagación hacia atrás hasta que se alcance el número especificado de iteraciones. Por último, devolverá los pesos de la línea de mejor ajuste.
Entrenando el modelo
lr = 0.0001 # Tasa de aprendizaje
itrs = 30 # Nº de iteraciones
modelo = LinearRegression()
Q0, Q1, pérdidas = modelo.train(x_train, y_train, lr, itrs)
# Salida Nº de Iteración vs Pérdida
for itr in range(len(pérdidas)):
print(f"Iteración = {itr+1}, Pérdida = {pérdidas[itr]}")Salida:
Iteración = 1, Pérdida = 6547.547538061649
Iteración = 2, Pérdida = 3016.791083711492
Iteración = 3, Pérdida = 1392.3048668536044
Iteración = 4, Pérdida = 644.8855797373262
Iteración = 5, Pérdida = 301.0011032250385
Iteración = 6, Pérdida = 142.78129818453215
.
.
.
.
Iteración = 27, Pérdida = 7.949420840198964
Iteración = 28, Pérdida = 7.949411555664398
Iteración = 29, Pérdida = 7.949405538972356
Iteración = 30, Pérdida = 7.949401025888949Se puede observar que en la 1ª iteración, la pérdida es máxima, y en las iteraciones posteriores, esta pérdida disminuye y alcanza su valor mínimo al final de la 30ª iteración.
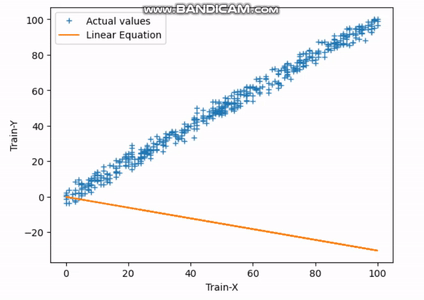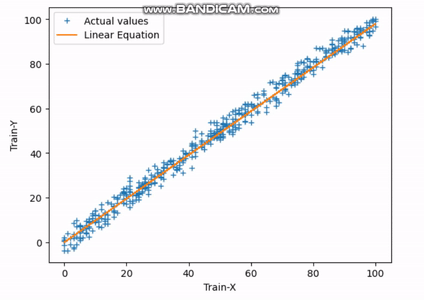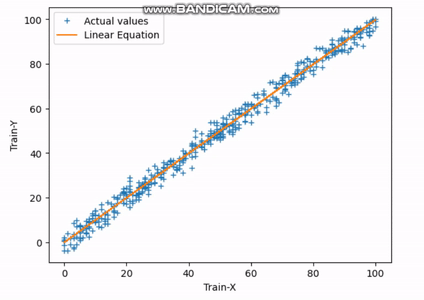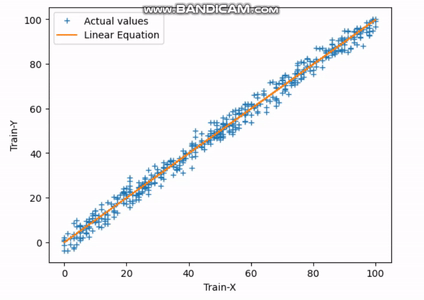 Fig.3 Encontrando la línea de mejor ajuste | Imagen del autor
Fig.3 Encontrando la línea de mejor ajuste | Imagen del autor
El gif anterior indica cómo la línea recta alcanza su línea de mejor ajuste después de completar la 30ª iteración.
Predicción final
# Predicción sobre los datos de prueba
y_pred = Q0 + x_test * Q1
print(f"Línea de mejor ajuste: (Y = {Q1}*X + {Q0})")
# Graficar la línea de regresión con los puntos de datos reales
plt.plot(x_test, y_test, "+", label="Puntos de datos")
plt.plot(x_test, y_pred, label="Valores predichos")
plt.xlabel("X-Test")
plt.ylabel("Y-Test")
plt.legend()
plt.show()Esta es la ecuación final de la línea de mejor ajuste.
Línea de mejor ajuste: (Y = 1.0068007107347927*X + -0.653638673779529)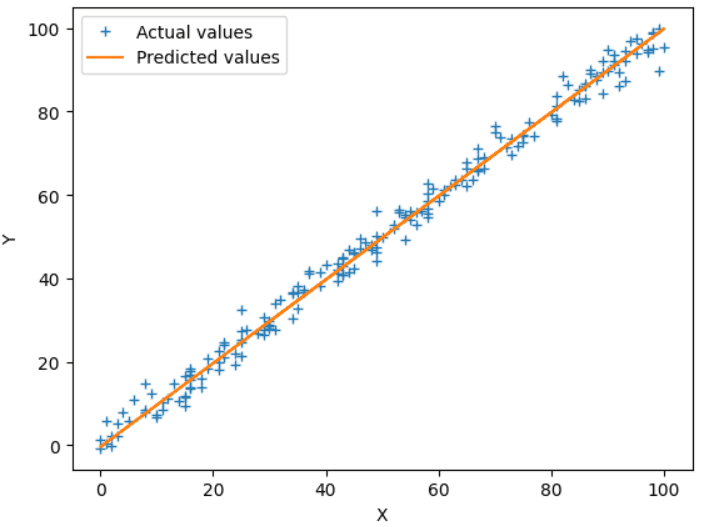 Fig.4 Salida real vs predicha | Imagen del autor
Fig.4 Salida real vs predicha | Imagen del autor
El gráfico anterior muestra la línea de mejor ajuste (naranja) y los valores reales (azul +) del conjunto de prueba. También se pueden ajustar los hiperparámetros, como la tasa de aprendizaje o el número de iteraciones, para aumentar la precisión y la exactitud.
Regresión lineal (usando la biblioteca Sklearn)
En la sección anterior, hemos visto cómo implementar la regresión lineal univariante desde cero. Pero también hay una biblioteca incorporada de Sklearn que se puede usar directamente para implementar la regresión lineal. Discutamos brevemente cómo podemos hacerlo.
Usaremos el mismo conjunto de datos, pero si lo desea, también puede usar uno diferente. Debe importar dos bibliotecas adicionales de la siguiente manera.
# Importación de bibliotecas adicionales
de sklearn.linear_model import LinearRegression
de sklearn.model_selection import train_test_splitCarga del conjunto de datos
df = pd.read_csv("lr_dataset.csv")
# Eliminar valores nulos
df = df.dropna()
# División de entrenamiento-prueba
Y = df.Y
X = df.drop("Y", axis=1)
x_train, x_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=42
)Anteriormente, teníamos que realizar la división de entrenamiento-prueba manualmente utilizando la biblioteca numpy. Pero ahora podemos utilizar la función train_test_split() de sklearn para dividir directamente los datos en los conjuntos de entrenamiento y prueba simplemente especificando el tamaño de la prueba.
Entrenamiento del modelo y predicciones
modelo = LinearRegression()
modelo.fit(x_train, y_train)
y_pred = modelo.predict(x_test)
# Graficar la línea de regresión con los puntos de datos reales
plt.plot(x_test, y_test, "+", label="Valores reales")
plt.plot(x_test, y_pred, label="Valores predichos")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.show()Ahora, no tenemos que escribir los códigos para la propagación hacia adelante, la propagación hacia atrás, la función de coste, etc. Ahora podemos utilizar directamente la clase LinearRegression() y entrenar el modelo en los datos de entrada. A continuación, se muestra la gráfica obtenida en los datos de prueba del modelo entrenado. Los resultados son similares a cuando implementamos el algoritmo por nuestra cuenta.
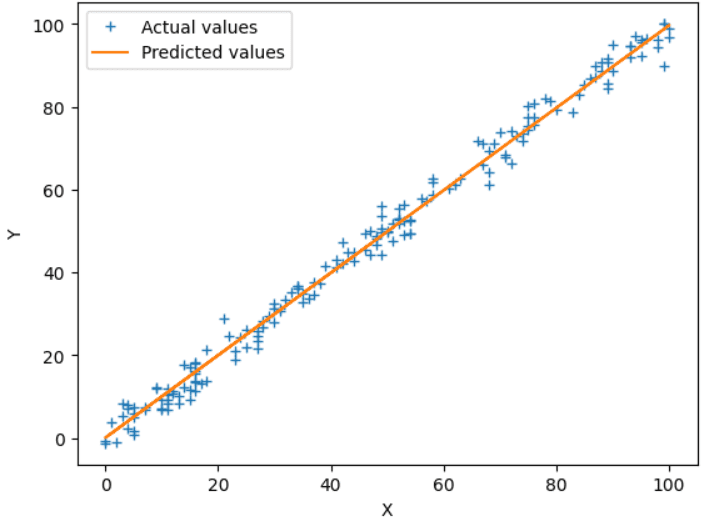 Fig.5 Salida del modelo de Sklearn | Imagen por el autor
Fig.5 Salida del modelo de Sklearn | Imagen por el autor
Referencias
- GeeksForGeeks: Regresión lineal de ML
Envolviéndolo
Enlace de Google Colab para el código completo – Código del tutorial de regresión lineal
En este artículo, hemos discutido exhaustivamente qué es la Regresión lineal, su intuición matemática y su implementación en Python tanto desde cero como usando la biblioteca sklearn. Este algoritmo es sencillo e intuitivo, por lo que ayuda a los principiantes a sentar una base sólida y a adquirir habilidades prácticas de codificación para hacer predicciones precisas utilizando Python.
Gracias por leer. Aryan Garg es un estudiante de Ingeniería Eléctrica de B.Tech., actualmente en el último año de su carrera de pregrado. Su interés se encuentra en el campo del Desarrollo Web y el Aprendizaje Automático. Ha seguido este interés y está ansioso por trabajar más en estas direcciones.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Está lista su solicitud de LLM para el público?
- Desafíos de la producción en masa de conducción autónoma en China.
- SRGANs Acortando la Brecha Entre Imágenes de Baja y Alta Resolución
- La mochila que resuelve el sesgo de ChatGPT Los modelos de lenguaje Backpack son métodos de inteligencia artificial alternativos para los transformadores.
- Aprende un idioma rápidamente con ChatGPT (Tutor de idiomas gratuito)
- Conozca LLM-Blender Un Nuevo Marco de Ensamblado para Lograr un Rendimiento Constantemente Superior al Aprovechar las Diversas Fortalezas de Múltiples Modelos de Lenguaje de Código Abierto (LLMs) de Gran Tamaño.
- Decodificando Glassdoor Ideas impulsadas por NLP para decisiones informadas





