Explorando opciones de resumen para Healthcare con Amazon SageMaker
Opciones de resumen para Healthcare con Amazon SageMaker
En el panorama de la salud en constante evolución de hoy en día, los médicos se enfrentan a grandes cantidades de datos clínicos de diversas fuentes, como notas de cuidadores, registros electrónicos de salud e informes de imágenes. Esta gran cantidad de información, aunque es esencial para la atención al paciente, también puede resultar abrumadora y consumir mucho tiempo para los profesionales médicos al filtrar y analizar. Resumir y extraer información de manera eficiente de estos datos es crucial para mejorar la atención al paciente y la toma de decisiones. La información resumida del paciente puede ser útil para diversos procesos posteriores, como la agregación de datos, la codificación efectiva de pacientes o la agrupación de pacientes con diagnósticos similares para su revisión.
La inteligencia artificial (IA) y el aprendizaje automático (AA) han demostrado un gran potencial para abordar estos desafíos. Los modelos pueden ser entrenados para analizar e interpretar grandes volúmenes de datos de texto, condensando eficazmente la información en resúmenes concisos. Al automatizar el proceso de resumen, los médicos pueden acceder rápidamente a información relevante, lo que les permite centrarse en la atención al paciente y tomar decisiones más informadas. Consulte el siguiente caso de estudio para obtener más información sobre un caso de uso del mundo real.
Amazon SageMaker, un servicio de AA completamente administrado, proporciona una plataforma ideal para alojar e implementar diversos modelos y enfoques de resumen basados en IA/AA. En esta publicación, exploramos diferentes opciones para implementar técnicas de resumen en SageMaker, que incluyen el uso de modelos fundacionales de Amazon SageMaker JumpStart, el ajuste fino de modelos pre-entrenados de Hugging Face y la construcción de modelos de resumen personalizados. También discutimos los pros y los contras de cada enfoque, lo que permite a los profesionales de la salud elegir la solución más adecuada para generar resúmenes concisos y precisos de datos clínicos complejos.
Dos términos importantes que debemos conocer antes de comenzar: pre-entrenado y ajuste fino. Un modelo pre-entrenado o fundacional es aquel que ha sido construido y entrenado en un gran corpus de datos, típicamente para conocimiento general del lenguaje. El ajuste fino es el proceso mediante el cual se proporciona a un modelo pre-entrenado otro conjunto de datos más específico del dominio para mejorar su rendimiento en una tarea específica. En un entorno de atención médica, esto significaría proporcionar al modelo algunos datos que incluyan frases y terminología relacionadas específicamente con la atención al paciente.
- Código de Destilación de Conocimiento y Pesos de SD-Small y SD-Tiny de código abierto
- Generación práctica de activos en 3D Una guía paso a paso
- Gigantesco Telescopio Adopta Robots de Mantenimiento Inteligentes
Construir modelos de resumen personalizados en SageMaker
Aunque es el enfoque que requiere más esfuerzo, algunas organizaciones pueden preferir construir modelos de resumen personalizados en SageMaker desde cero. Este enfoque requiere un conocimiento más profundo de los modelos de IA/AA y puede implicar crear una arquitectura de modelo desde cero o adaptar modelos existentes para satisfacer necesidades específicas. La construcción de modelos personalizados puede ofrecer una mayor flexibilidad y control sobre el proceso de resumen, pero también requiere más tiempo y recursos en comparación con enfoques que parten de modelos pre-entrenados. Es esencial evaluar cuidadosamente los beneficios y las desventajas de esta opción antes de continuar, ya que puede que no sea adecuada para todos los casos de uso.
Modelos fundacionales de SageMaker JumpStart
Una excelente opción para implementar resúmenes en SageMaker es utilizar modelos fundacionales de JumpStart. Estos modelos, desarrollados por destacadas organizaciones de investigación en IA, ofrecen una variedad de modelos de lenguaje pre-entrenados optimizados para diversas tareas, incluida la resumización de texto. SageMaker JumpStart ofrece dos tipos de modelos fundacionales: modelos propietarios y modelos de código abierto. SageMaker JumpStart también ofrece elegibilidad para HIPAA, lo que lo hace útil para cargas de trabajo de atención médica. En última instancia, es responsabilidad del cliente garantizar el cumplimiento, así que asegúrese de seguir los pasos adecuados. Consulte la Arquitectura para la seguridad y el cumplimiento de HIPAA en Amazon Web Services para obtener más detalles.
Modelos fundacionales propietarios
Los modelos propietarios, como los modelos Jurassic de AI21 y el modelo Cohere Generate de Cohere, se pueden descubrir a través de SageMaker JumpStart en la Consola de administración de AWS y actualmente se encuentran en versión preliminar. Utilizar modelos propietarios para el resumen es ideal cuando no es necesario ajustar finamente el modelo con datos personalizados. Esto ofrece una solución fácil de usar y lista para usar que puede cumplir con los requisitos de resumen con una configuración mínima. Al utilizar las capacidades de estos modelos pre-entrenados, puede ahorrar tiempo y recursos que de otro modo se invertirían en entrenar y ajustar finamente un modelo personalizado. Además, los modelos propietarios suelen venir con API y SDK fáciles de usar, lo que agiliza el proceso de integración con sus sistemas y aplicaciones existentes. Si sus necesidades de resumen se pueden satisfacer con modelos propietarios pre-entrenados sin requerir una personalización o ajuste fino específico, ofrecen una solución conveniente, rentable y eficiente para sus tareas de resumen de texto. Debido a que estos modelos no están entrenados específicamente para casos de uso en atención médica, la calidad no puede garantizarse para lenguaje médico sin ajuste fino.
Jurassic-2 Grande Instruct es un modelo de lenguaje grande (LLM) desarrollado por AI21 Labs, optimizado para instrucciones en lenguaje natural y aplicable a diversas tareas de lenguaje. Ofrece una API y un SDK fáciles de usar, equilibrando calidad y asequibilidad. Se utiliza ampliamente para generar copias de marketing, alimentar chatbots y resumir texto.
En la consola de SageMaker, navegue hasta SageMaker JumpStart, encuentre el modelo AI21 Jurassic-2 Grande Instruct y elija Probar el modelo.

Si desea implementar el modelo en un punto de enlace de SageMaker que administre, puede seguir los pasos en este cuaderno de muestra, que le muestra cómo implementar Jurassic-2 Large usando SageMaker.
Modelos base de código abierto
Los modelos de código abierto incluyen los modelos FLAN T5, Bloom y GPT-2 que se pueden descubrir a través de SageMaker JumpStart en la interfaz de Amazon SageMaker Studio, SageMaker JumpStart en la consola de SageMaker y las API de SageMaker JumpStart. Estos modelos se pueden ajustar y implementar en puntos de enlace bajo su cuenta de AWS, lo que le brinda la propiedad completa de los pesos del modelo y los códigos de script.
Flan-T5 XL es un modelo potente y versátil diseñado para una amplia gama de tareas de lenguaje. Al ajustar el modelo con sus datos específicos del dominio, puede optimizar su rendimiento para su caso de uso particular, como la resumen de texto o cualquier otra tarea de procesamiento de lenguaje natural. Para obtener detalles sobre cómo ajustar finamente Flan-T5 XL utilizando la interfaz de usuario de SageMaker Studio, consulte la guía de instrucciones para ajustar finamente FLAN T5 XL con Amazon SageMaker Jumpstart.
Ajuste fino de modelos preentrenados con Hugging Face en SageMaker
Una de las opciones más populares para implementar la summarización en SageMaker es el ajuste fino de modelos preentrenados utilizando la biblioteca Hugging Face Transformers. Hugging Face ofrece una amplia gama de modelos transformadores preentrenados diseñados específicamente para varias tareas de procesamiento de lenguaje natural (NLP), incluida la summarización de texto. Con la biblioteca Hugging Face Transformers, puede ajustar finamente estos modelos preentrenados con sus datos específicos del dominio utilizando SageMaker. Este enfoque tiene varias ventajas, como tiempos de entrenamiento más rápidos, mejor rendimiento en dominios específicos y un empaquetado y implementación de modelos más sencillos utilizando las herramientas y servicios integrados de SageMaker. Si no encuentra un modelo adecuado en SageMaker JumpStart, puede elegir cualquier modelo ofrecido por Hugging Face y ajustarlo finamente utilizando SageMaker.
Para comenzar a trabajar con un modelo y aprender sobre las capacidades de ML, todo lo que necesita hacer es abrir SageMaker Studio, encontrar un modelo preentrenado que desee utilizar en el Hugging Face Model Hub y elegir SageMaker como su método de implementación. Hugging Face le proporcionará el código para copiar, pegar y ejecutar en su cuaderno. ¡Es tan fácil como eso! No se requiere experiencia en ingeniería de ML.

La biblioteca Hugging Face Transformers permite a los desarrolladores trabajar en los modelos preentrenados y realizar tareas avanzadas como el ajuste fino, que exploramos en las siguientes secciones.
Provisionar recursos
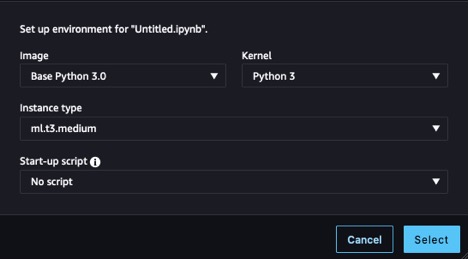
Antes de comenzar, necesitamos provisionar un cuaderno. Para obtener instrucciones, consulte los pasos 1 y 2 en Crear y entrenar un modelo de aprendizaje automático localmente. Para este ejemplo, utilizamos la configuración que se muestra en la siguiente captura de pantalla.
También necesitamos crear un bucket de Amazon Simple Storage Service (Amazon S3) para almacenar los datos de entrenamiento y los artefactos de entrenamiento. Para obtener instrucciones, consulte Crear un bucket.
Preparar el conjunto de datos
Para ajustar finamente nuestro modelo y tener un mejor conocimiento del dominio, necesitamos obtener datos adecuados para la tarea. Cuando se entrena para un caso de uso empresarial, deberá realizar una serie de tareas de ingeniería de datos para preparar sus propios datos para el entrenamiento. Esas tareas están fuera del alcance de esta publicación. Para este ejemplo, hemos generado algunos datos sintéticos para emular notas de enfermería y los hemos almacenado en Amazon S3. Almacenar nuestros datos en Amazon S3 nos permite diseñar nuestras cargas de trabajo para el cumplimiento de HIPAA. Comenzamos obteniendo esas notas y cargándolas en la instancia donde se está ejecutando nuestro cuaderno:
from datasets import load_dataset
dataset = load_dataset("csv", data_files={
"train": "s3://" + bucket_name + train_data_path,
"validation": "s3://" + bucket_name + test_data_path
})Las notas están compuestas por una columna que contiene la entrada completa, nota, y una columna que contiene una versión abreviada ejemplificando cuál debería ser nuestra salida deseada, resumen. El propósito de utilizar este conjunto de datos es mejorar el vocabulario biológico y médico de nuestro modelo para que esté más ajustado a la tarea de resumir en un contexto de atención médica, llamada ajuste fino de dominio, y mostrar a nuestro modelo cómo estructurar su salida resumida. En algunos casos de resumación, es posible que queramos crear un resumen abstracto de un artículo o una sinopsis de una reseña en una línea, pero en este caso, estamos tratando de hacer que nuestro modelo genere una versión abreviada de los síntomas y las acciones tomadas hasta ahora para un paciente.
Cargar el modelo
El modelo que utilizamos como base es una versión de Pegasus de Google, disponible en el Hugging Face Hub, llamado pegasus-xsum. Ya está preentrenado para la tarea de resumación, por lo que nuestro proceso de ajuste fino se puede centrar en ampliar su conocimiento de dominio. Modificar la tarea que ejecuta nuestro modelo es un tipo diferente de ajuste fino que no se cubre en esta publicación. La biblioteca Transformer nos proporciona una clase para cargar la definición del modelo desde nuestro model_checkpoint: google/pegasus-xsum. Esto cargará el modelo desde el hub e instanciarlo en nuestro cuaderno para poder usarlo más adelante. Como pegasus-xsum es un modelo de secuencia a secuencia (sequence-to-sequence), queremos usar el tipo Seq2Seq de la clase AutoModel:
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)Ahora que tenemos nuestro modelo, es hora de centrarnos en los otros componentes que nos permitirán ejecutar nuestro bucle de entrenamiento.
Crear un tokenizador
El primero de estos componentes es el tokenizador. La tokenización es el proceso mediante el cual las palabras de los datos de entrada se transforman en representaciones numéricas que nuestro modelo puede entender. Nuevamente, la biblioteca Transformer proporciona una clase para cargar la definición del tokenizador desde el mismo punto de control que usamos para instanciar el modelo:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Con este objeto tokenizador, podemos crear una función de preprocesamiento y aplicarla a nuestro conjunto de datos para obtener tokens listos para ser alimentados al modelo. Finalmente, formateamos la salida tokenizada y eliminamos las columnas que contienen nuestro texto original, porque el modelo no podrá interpretarlas. Ahora nos queda una entrada tokenizada lista para ser alimentada al modelo. Vea el siguiente código:
tokenized_datasets = dataset.map(preprocess_function, batched=True)
tokenized_datasets.set_format("torch")
tokenized_datasets = tokenized_datasets.remove_columns(
dataset["train"].column_names
)Crear un agrupador de datos y un optimizador
Con nuestros datos tokenizados y nuestro modelo instanciado, casi estamos listos para ejecutar un bucle de entrenamiento. Los siguientes componentes que queremos crear son el agrupador de datos y el optimizador. El agrupador de datos es otra clase proporcionada por Hugging Face a través de la biblioteca Transformers, que usamos para crear lotes de nuestros datos tokenizados para el entrenamiento. Podemos construir esto fácilmente utilizando los objetos tokenizador y modelo que ya tenemos, simplemente encontrando el tipo de clase correspondiente que hemos utilizado anteriormente para nuestro modelo (Seq2Seq) para la clase del agrupador. La función del optimizador es mantener el estado de entrenamiento y actualizar los parámetros en función de nuestra pérdida de entrenamiento a medida que avanzamos en el bucle. Para crear un optimizador, podemos importar el paquete optim del módulo torch, donde hay disponibles varios algoritmos de optimización. Algunos comunes que es posible que hayas encontrado antes son Descenso de Gradiente Estocástico (SGD) y Adam, este último se aplica en nuestro ejemplo. El constructor de Adam toma los parámetros del modelo y la tasa de aprendizaje parametrizada para la ejecución de entrenamiento específica. Vea el siguiente código:
from transformers import DataCollatorForSeq2Seq
from torch.optim import Adam
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
optimizer = Adam(model.parameters(), lr=learning_rate)Construir el acelerador y el programador de tasas de aprendizaje
Los últimos pasos antes de comenzar el entrenamiento son construir el acelerador y el programador de tasas de aprendizaje. El acelerador proviene de una biblioteca diferente (hemos estado utilizando principalmente Transformers) producida por Hugging Face, llamada Accelerate, y abstraerá la lógica requerida para administrar los dispositivos durante el entrenamiento (por ejemplo, utilizando varias GPU). Para el último componente, volvemos a utilizar la útil biblioteca Transformers para implementar nuestro programador de tasas de aprendizaje. Al especificar el tipo de programador, el número total de pasos de entrenamiento en nuestro bucle y el optimizador creado anteriormente, la función get_scheduler devuelve un objeto que nos permite ajustar nuestra tasa de aprendizaje inicial a lo largo del proceso de entrenamiento:
from accelerate import Accelerator
from transformers import get_scheduler
acelerador = Accelerator()
modelo, optimizador = acelerador.prepare(
modelo, optimizador
)
programador_lr = get_scheduler(
"linear",
optimizer=optimizador,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Configurar un trabajo de entrenamiento
¡Ahora estamos completamente listos para el entrenamiento! Configuremos un trabajo de entrenamiento, comenzando por instanciar training_args usando la biblioteca Transformers y elegir valores de parámetros. Podemos pasar estos, junto con nuestros otros componentes preparados y conjunto de datos, directamente al entrenador y comenzar el entrenamiento, como se muestra en el siguiente código. Dependiendo del tamaño de su conjunto de datos y los parámetros elegidos, esto puede llevar una cantidad significativa de tiempo.
from transformers import Seq2SeqTrainer
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="output/",
save_total_limit=1,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
evaluation_strategy="epoch",
logging_dir="output/",
load_best_model_at_end=True,
disable_tqdm=True,
logging_first_step=True,
logging_steps=1,
save_strategy="epoch",
predict_with_generate=True
)
entrenador = Seq2SeqTrainer(
model=modelo,
tokenizer=tokenizer,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
optimizers=(optimizador, programador_lr)
)
entrenador.train()Para operacionalizar este código, podemos empaquetarlo como un archivo de punto de entrada y llamarlo a través de un trabajo de entrenamiento de SageMaker. Esto nos permite separar la lógica que acabamos de construir de la llamada de entrenamiento y permite que SageMaker ejecute el entrenamiento en una instancia separada.
Empaquetar el modelo para inferencia
Después de que se haya ejecutado el entrenamiento, el objeto del modelo está listo para ser utilizado para la inferencia. Como buena práctica, guardemos nuestro trabajo para su uso futuro. Necesitamos crear nuestros artefactos del modelo, comprimirlos juntos y cargar nuestro archivo tarball en Amazon S3 para su almacenamiento. Para preparar nuestro modelo para comprimirlo, necesitamos desempaquetar el modelo ahora afinado, luego guardar el binario del modelo y los archivos de configuración asociados. También necesitamos guardar nuestro tokenizador en el mismo directorio en el que guardamos nuestros artefactos del modelo para que esté disponible cuando usemos el modelo para la inferencia. Nuestra carpeta model_dir debería verse ahora como el siguiente código:
config.json pytorch_model.bin tokenizer_config.json
generation_config.json special_tokens_map.json tokenizer.jsonLo único que queda es ejecutar un comando tar para comprimir nuestro directorio y subir el archivo tar.gz a Amazon S3:
modelo_sin_envoltura = acelerador.unwrap_model(entrenador.modelo)
modelo_sin_envoltura.save_pretrained('model_dir', save_function=acelerador.save)
tokenizer.save_pretrained('model_dir')
!cd model_dir/ && tar -czvf model.tar.gz *
!mv model_dir/model.tar.gz ./
with open("model.tar.gz", "rb") as f:
s3.upload_fileobj(f, bucket_name, artifact_path + "model/model.tar.gz")Nuestro modelo recién afinado ahora está listo y disponible para ser utilizado para la inferencia.
Realizar inferencia
Para utilizar este artefacto del modelo para la inferencia, abra un nuevo archivo y use el siguiente código, modificando el parámetro model_data para que se ajuste a la ubicación de guardado de su artefacto en Amazon S3. El constructor HuggingFaceModel reconstruirá nuestro modelo a partir del punto de control que guardamos en model.tar.gz, que luego podemos implementar para la inferencia utilizando el método deploy. La implementación del punto final tomará unos minutos.
from sagemaker.huggingface import HuggingFaceModel
from sagemaker import get_execution_role
role = get_execution_role()
modelo_huggingface = HuggingFaceModel(
model_data=”s3://{bucket_name}/{artifact_path}/model/model.tar.gz”,
role=role,
transformers_version=”4.26”,
pytorch_version=”1.13”,
py_version=”py39”
)
predictor = modelo_huggingface.deploy(
initial_instance_count=1,
instance_type=”ml.m5.xlarge”
)Después de implementar el punto final, podemos usar el predictor que hemos creado para probarlo. Pase el método predict una carga de datos y ejecute la celda, y obtendrá la respuesta de su modelo afinado:
data = {
"inputs": "Texto para resumir”
}
predictor.predict(data)Resultados
Para ver el beneficio de ajustar finamente un modelo, hagamos una prueba rápida. La siguiente tabla incluye una indicación y los resultados de pasar esa indicación al modelo antes y después del ajuste fino.
| Indicación | Respuesta sin ajuste fino | Respuesta con ajuste fino |
| Resuma los síntomas que el paciente está experimentando. El paciente es un hombre de 45 años con quejas de dolor en el pecho subesternal que se irradia hacia el brazo izquierdo. El dolor se produce de forma repentina mientras hacía trabajos de jardinería, asociado con una ligera dificultad para respirar y diaforesis. A la llegada, la frecuencia cardíaca del paciente era de 120, la frecuencia respiratoria de 24 y la presión arterial de 170/95. Se realizó un electrocardiograma de 12 derivaciones a la llegada al departamento de emergencias y se administraron tres tabletas de nitroglicerina sublingual sin alivio del dolor en el pecho. El electrocardiograma muestra elevación del segmento ST en las derivaciones anteriores, lo que demuestra un infarto agudo de miocardio anterior. Hemos contactado al laboratorio de cateterismo cardíaco y nos estamos preparando para la cateterización cardíaca por parte del cardiólogo. | Presentamos un caso de infarto agudo de miocardio. | Dolor en el pecho, infarto agudo de miocardio anterior, intervención percutánea coronaria. |
Como puede ver, nuestro modelo ajustado finamente utiliza la terminología médica de manera diferente y hemos podido cambiar la estructura de la respuesta para adaptarla a nuestros propósitos. Tenga en cuenta que los resultados dependen de su conjunto de datos y de las decisiones de diseño tomadas durante el entrenamiento. Su versión del modelo podría ofrecer resultados muy diferentes.
Limpieza
Cuando haya terminado con su cuaderno de SageMaker, asegúrese de apagarlo para evitar costos por recursos en ejecución prolongada. Tenga en cuenta que al apagar la instancia perderá todos los datos almacenados en la memoria efímera de la instancia, por lo que debe guardar todo su trabajo en almacenamiento persistente antes de realizar la limpieza. También deberá ir a la página de Endpoints en la consola de SageMaker y eliminar cualquier endpoint implementado para inferencia. Para eliminar todos los artefactos, también deberá ir a la consola de Amazon S3 para eliminar los archivos cargados en su bucket.
Conclusión
En esta publicación, exploramos diversas opciones para implementar técnicas de resumen de texto en SageMaker para ayudar a los profesionales de la salud a procesar y extraer información de grandes cantidades de datos clínicos de manera eficiente. Discutimos el uso de los modelos base de SageMaker Jumpstart, el ajuste fino de modelos pre-entrenados de Hugging Face y la creación de modelos personalizados de resumen. Cada enfoque tiene sus propias ventajas y desventajas, adaptándose a diferentes necesidades y requisitos.
La creación de modelos personalizados de resumen en SageMaker permite mucha flexibilidad y control, pero requiere más tiempo y recursos que el uso de modelos pre-entrenados. Los modelos base de SageMaker Jumpstart ofrecen una solución fácil de usar y rentable para organizaciones que no requieren una personalización específica o ajuste fino, así como algunas opciones simplificadas de ajuste fino. El ajuste fino de modelos pre-entrenados de Hugging Face ofrece tiempos de entrenamiento más rápidos, un mejor rendimiento específico del dominio y una integración perfecta con las herramientas y servicios de SageMaker en un amplio catálogo de modelos, pero requiere cierto esfuerzo de implementación. En el momento de escribir esta publicación, Amazon ha anunciado otra opción, Amazon Bedrock, que ofrecerá capacidades de resumen en un entorno aún más gestionado.
Al comprender los pros y los contras de cada enfoque, los profesionales de la salud y las organizaciones pueden tomar decisiones informadas sobre la solución más adecuada para generar resúmenes concisos y precisos de datos clínicos complejos. En última instancia, el uso de modelos de resumen basados en IA/ML en SageMaker puede mejorar significativamente la atención al paciente y la toma de decisiones al permitir que los profesionales médicos accedan rápidamente a información relevante y se centren en brindar una atención de calidad.
Recursos
Para obtener el script completo discutido en esta publicación y algunos datos de muestra, consulte el repositorio de GitHub. Para obtener más información sobre cómo ejecutar cargas de trabajo de ML en AWS, consulte los siguientes recursos:
- Taller de Hugging Face en Amazon SageMaker
- Ejemplos de Hugging Face Transformers en Amazon SageMaker
- Technology Innovation Institute entrena el modelo base Falcon LLM 40B de vanguardia en Amazon SageMaker
- Entrenamiento de modelos de lenguaje grandes en Amazon SageMaker: Mejores prácticas
- Cómo Forethought ahorra más del 66% en costos para modelos de IA generativos utilizando Amazon SageMaker
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 4 Herramientas de IA para trabajar con PDFs – Además de herramientas adicionales de bonificación
- Identificación Lingüística con Python
- Análisis de acordes de jazz con Transformers
- Principales artículos de Visión por Computadora durante la semana del 24/7 al 31/7
- 10 Mejores Herramientas de Intercambio de Caras de IA (Agosto 2023)
- API de Pronóstico Un Ejemplo con Django y Google Trends
- ChatGPT y la ingeniería avanzada de instrucciones impulsando la evolución de la IA