ControlNet en 🧨 Difusores
'ControlNet en 🧨 Difusores' can be condensed to 'ControlNet en Difusores'
![]()
Desde que Stable Diffusion causó sensación en el mundo, las personas han estado buscando formas de tener más control sobre los resultados del proceso de generación. ControlNet proporciona una interfaz mínima que permite a los usuarios personalizar en gran medida el proceso de generación. ¡Con ControlNet, los usuarios pueden condicionar fácilmente la generación con diferentes contextos espaciales como un mapa de profundidad, un mapa de segmentación, un garabato, puntos clave, ¡y mucho más!
Podemos convertir un dibujo animado en una foto realista con una increíble coherencia.
| Realistic Lofi Girl |
|---|
 |
O incluso usarlo como tu diseñador de interiores.
- Creando Inteligencia Artificial de Preservación de Privacidad con Substra
- Aprendizaje Federado utilizando Hugging Face y Flower
- Acelerando la Inferencia de Difusión Estable en CPUs Intel
| Antes | Después |
|---|---|
 |
 |
Puedes convertir tu garabato en un dibujo artístico.
| Antes | Después |
|---|---|
 |
 |
También puedes dar vida a algunos de los famosos logotipos.
| Antes | Después |
|---|---|
 |
Con ControlNet, el cielo es el límite 🌠
En esta publicación de blog, primero presentamos el StableDiffusionControlNetPipeline y luego mostramos cómo se puede aplicar para varias condiciones de control. ¡Empecemos a controlar!
ControlNet: TL;DR
ControlNet fue introducido en Adding Conditional Control to Text-to-Image Diffusion Models por Lvmin Zhang y Maneesh Agrawala. Introduce un marco que permite admitir varios contextos espaciales que pueden servir como condicionantes adicionales para modelos de difusión como Stable Diffusion. La implementación de los difusores se adapta del código fuente original .
El entrenamiento de ControlNet consta de los siguientes pasos:
- Clonar los parámetros preentrenados de un modelo de difusión, como el UNet latente de Stable Diffusion, (denominado “copia entrenable”) mientras se mantienen los parámetros preentrenados por separado (“copia bloqueada”). Se hace para que la copia bloqueada de los parámetros pueda preservar el vasto conocimiento aprendido de un gran conjunto de datos, mientras que la copia entrenable se utiliza para aprender los aspectos específicos de la tarea.
- Las copias entrenable y bloqueada de los parámetros se conectan mediante capas de “convolución cero” (consulte aquí para obtener más información), que se optimizan como parte del marco de ControlNet. Este es un truco de entrenamiento para preservar la semántica ya aprendida por el modelo congelado a medida que se entrenan las nuevas condiciones.
De manera pictórica, el entrenamiento de un ControlNet se ve así:
 El diagrama se toma de aquí .
El diagrama se toma de aquí .
Una muestra del conjunto de entrenamiento para un entrenamiento similar a ControlNet se ve así (la condición adicional es a través de mapas de bordes):
| Indicación | Imagen Original | Condicionamiento |
|---|---|---|
| “pájaro” |  |
 |
De manera similar, si condicionáramos ControlNet con mapas de segmentación semántica, una muestra de entrenamiento se vería así:
| Indicación | Imagen Original | Condicionamiento |
|---|---|---|
| “casa grande” |  |
 |
Cada nuevo tipo de condicionamiento requiere entrenar una copia nueva de los pesos de ControlNet. ¡El artículo propuso 8 modelos de condicionamiento diferentes que son compatibles en Diffusers!
Para la inferencia, se necesitan tanto los pesos de los modelos de difusión pre-entrenados como los pesos entrenados de ControlNet. Por ejemplo, usar Stable Diffusion v1-5 con un punto de control de ControlNet requiere aproximadamente 700 millones de parámetros más en comparación con solo usar el modelo original de Stable Diffusion, lo que hace que ControlNet sea un poco más costoso en memoria para la inferencia.
Debido a que los modelos de difusión pre-entrenados están bloqueados durante el entrenamiento, solo es necesario cambiar los parámetros de ControlNet al utilizar un condicionamiento diferente. Esto hace que sea bastante simple implementar múltiples pesos de ControlNet en una aplicación, como veremos a continuación.
El StableDiffusionControlNetPipeline
Antes de comenzar, queremos agradecer enormemente al colaborador de la comunidad Takuma Mori por liderar la integración de ControlNet en Diffusers ❤️.
Para experimentar con ControlNet, Diffusers expone el StableDiffusionControlNetPipeline similar a los otros pipelines de Diffusers. Central en el StableDiffusionControlNetPipeline está el argumento controlnet, que nos permite proporcionar una instancia específica de ControlNetModel entrenado manteniendo los pesos pre-entrenados del modelo de difusión iguales.
Exploraremos diferentes casos de uso con el StableDiffusionControlNetPipeline en esta publicación de blog. El primer modelo de ControlNet que vamos a analizar es el modelo Canny, que es uno de los modelos más populares que generó algunas de las imágenes asombrosas que seguramente estás viendo en internet.
Te invitamos a ejecutar los fragmentos de código que se muestran en las secciones a continuación con este Cuaderno de Colab.
Antes de comenzar, asegurémonos de tener todas las bibliotecas necesarias instaladas:
pip install diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.gitPara procesar diferentes condicionamientos dependiendo del ControlNet elegido, también necesitamos instalar algunas dependencias adicionales:
- OpenCV
- controlnet-aux: una colección simple de modelos de preprocesamiento para ControlNet
pip install opencv-contrib-python
pip install controlnet_auxUtilizaremos la famosa pintura “Girl With A Pearl” para este ejemplo. Entonces, descarguemos la imagen y echemos un vistazo:
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image
A continuación, pasaremos la imagen por el preprocesador de Canny:
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_imageComo podemos ver, es básicamente detección de bordes:

Ahora, cargamos el modelo runwaylml/stable-diffusion-v1-5 y el modelo ControlNet para bordes canny. Los modelos se cargan en media precisión (torch.dtype) para permitir una inferencia rápida y eficiente en memoria.
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)En lugar de utilizar el programador PNDMScheduler predeterminado de Stable Diffusion, utilizamos uno de los programadores de modelos de difusión más rápidos actualmente, llamado UniPCMultistepScheduler. Elegir un programador mejorado puede reducir drásticamente el tiempo de inferencia; en nuestro caso, podemos reducir el número de pasos de inferencia de 50 a 20, manteniendo más o menos la misma calidad de generación de imágenes. Se puede encontrar más información sobre los programadores aquí.
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)En lugar de cargar directamente nuestra canalización en la GPU, habilitamos la descarga inteligente de la CPU, que se puede lograr con la función enable_model_cpu_offload.
Recuerde que durante la inferencia de modelos de difusión, como Stable Diffusion, no solo se requiere un componente del modelo, sino múltiples componentes del modelo que se ejecutan secuencialmente. En el caso de Stable Diffusion con ControlNet, primero utilizamos el codificador de texto CLIP, luego el modelo de difusión unet y el control net, luego el decodificador VAE y finalmente ejecutamos un verificador de seguridad. La mayoría de los componentes solo se ejecutan una vez durante el proceso de difusión y, por lo tanto, no es necesario que ocupen memoria de la GPU todo el tiempo. Al habilitar la descarga inteligente del modelo, nos aseguramos de que cada componente se cargue en la GPU solo cuando sea necesario, lo que nos permite ahorrar significativamente el consumo de memoria sin ralentizar significativamente la inferencia.
Nota: Al ejecutar enable_model_cpu_offload, no mueva manualmente la canalización a la GPU con .to("cuda"): una vez que se habilita la descarga de la CPU, la canalización se encarga automáticamente de la administración de la memoria de la GPU.
pipe.enable_model_cpu_offload()Finalmente, queremos aprovechar al máximo la increíble aceleración de la capa de atención FlashAttention/xformers, ¡así que vamos a habilitar esto! Si este comando no funciona para usted, es posible que no tenga xformers instalado correctamente. En este caso, simplemente puede omitir la siguiente línea de código.
pipe.enable_xformers_memory_efficient_attention()Ahora estamos listos para ejecutar la canalización ControlNet.
Todavía proporcionamos una frase para guiar el proceso de generación de imágenes, como lo haríamos normalmente con una canalización de imagen a imagen de Stable Diffusion. Sin embargo, ControlNet permitirá mucho más control sobre la imagen generada porque podremos controlar la composición exacta en la imagen generada con la imagen de bordes canny que acabamos de crear.
Será divertido ver algunas imágenes en las que las celebridades contemporáneas posan para esta misma pintura del siglo XVII. Y es realmente fácil hacerlo con ControlNet, ¡todo lo que tenemos que hacer es incluir los nombres de estas celebridades en la frase!
Primero, creemos una función auxiliar simple para mostrar imágenes como una cuadrícula.
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return gridA continuación, definimos las indicaciones de entrada y establecemos una semilla para la reproducibilidad.
prompt = ", mejor calidad, extremadamente detallado"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]Finalmente, ¡podemos ejecutar el pipeline y mostrar la imagen!
output = pipe(
prompt,
canny_image,
negative_prompt=["monocromo, baja resolución, mala anatomía, peor calidad, baja calidad"] * 4,
num_inference_steps=20,
generator=generator,
)
image_grid(output.images, 2, 2)
¡Podemos combinar sin esfuerzo ControlNet con el ajuste fino también! Por ejemplo, podemos ajustar finamente un modelo con DreamBooth y usarlo para representarnos en diferentes escenas.
En esta publicación, vamos a utilizar a nuestro querido Mr Potato Head como ejemplo para mostrar cómo utilizar ControlNet con DreamBooth.
Podemos utilizar el mismo ControlNet. Sin embargo, en lugar de utilizar el Stable Diffusion 1.5, vamos a cargar el modelo de Mr Potato Head en nuestro pipeline: Mr Potato Head es un modelo de Stable Diffusion ajustado finamente con el concepto de Mr Potato Head utilizando Dreambooth 🥔
¡Vamos a ejecutar los comandos anteriores de nuevo, manteniendo el mismo controlnet!
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()¡Ahora hagamos que Mr Potato se ponga en posición para Johannes Vermeer!
generator = torch.manual_seed(2)
prompt = "una foto de Mr Potato Head de sks, mejor calidad, extremadamente detallado"
output = pipe(
prompt,
canny_image,
negative_prompt="monocromo, baja resolución, mala anatomía, peor calidad, baja calidad",
num_inference_steps=20,
generator=generator,
)
output.images[0]Es notable que Mr Potato Head no es el mejor candidato, pero hizo todo lo posible y hizo un buen trabajo capturando parte de la esencia 🍟

Otra aplicación exclusiva de ControlNet es que podemos tomar una pose de una imagen y reutilizarla para generar una imagen diferente con la misma pose exacta. Así que en este próximo ejemplo, ¡vamos a enseñar a los superhéroes a hacer yoga usando Open Pose ControlNet!
Primero, necesitaremos obtener algunas imágenes de personas haciendo yoga:
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)
Ahora extrayamos las poses de yoga utilizando los preprocesadores de OpenPose que están disponibles de manera práctica a través de controlnet_aux.
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)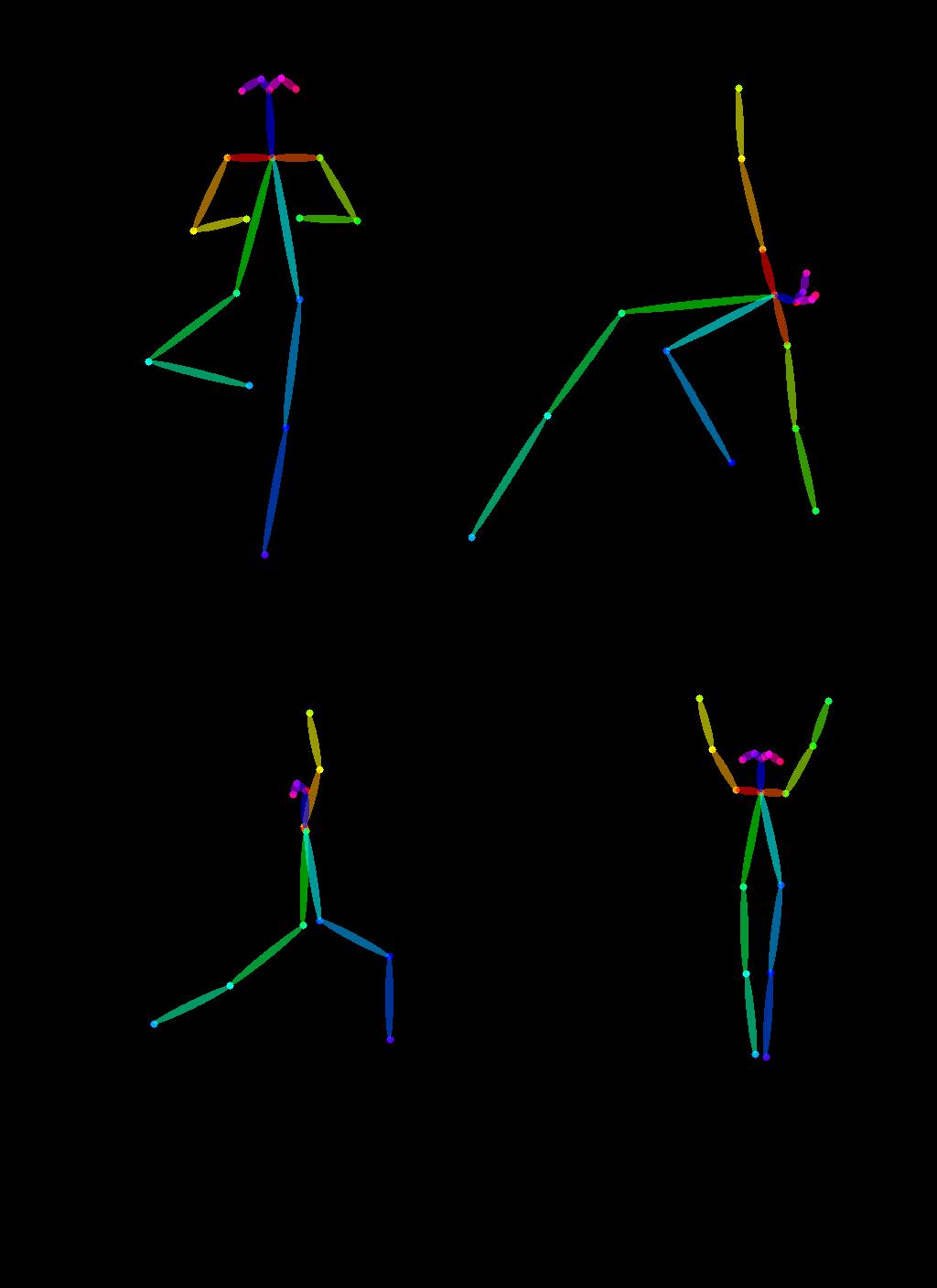
Para utilizar estas poses de yoga para generar nuevas imágenes, creemos un Open Pose ControlNet. Generaremos algunas imágenes de superhéroes, pero en las poses de yoga mostradas anteriormente. ¡Vamos allá! 🚀
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()¡Ahora es hora de hacer yoga!
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "personaje de superhéroe, mejor calidad, extremadamente detallado"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monocromo, baja resolución, mala anatomía, peor calidad, baja calidad"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)
Combinando múltiples acondicionamientos
Se pueden combinar múltiples acondicionamientos de ControlNet para generar una sola imagen. Pase una lista de ControlNets al constructor del pipeline y una lista correspondiente de acondicionamientos a __call__.
Cuando se combinan acondicionamientos, es útil enmascarar los acondicionamientos para que no se superpongan. En el ejemplo, enmascaramos el centro del mapa de Canny donde se encuentra el acondicionamiento de la pose.
También puede ser útil variar las escalas de controlnet_conditioning_scale para enfatizar un acondicionamiento sobre el otro.
Acondicionamiento de Canny
La imagen original

Preparando el acondicionamiento
from diffusers.utils import load_image
from PIL import Image
import cv2
import numpy as np
from diffusers.utils import load_image
canny_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)
low_threshold = 100
high_threshold = 200
canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
# anulamos las columnas centrales de la imagen donde se superpondrá la pose
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0
canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image)
Acondicionamiento de Openpose
La imagen original

Preparando el acondicionamiento
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image)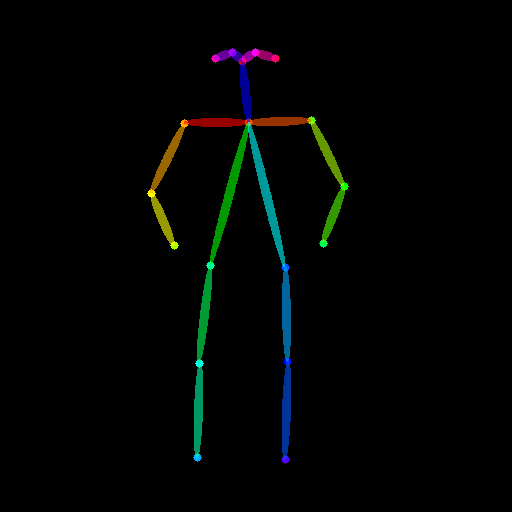
Ejecución de ControlNet con múltiples acondicionamientos
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = [
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
]
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
prompt = "un gigante parado en un paisaje de fantasía, mejor calidad"
negative_prompt = "monocromo, baja resolución, mala anatomía, peor calidad, baja calidad"
generator = torch.Generator(device="cpu").manual_seed(1)
images = [openpose_image, canny_image]
image = pipe(
prompt,
images,
num_inference_steps=20,
generator=generator,
negative_prompt=negative_prompt,
controlnet_conditioning_scale=[1.0, 0.8],
).images[0]
image.save("./multi_controlnet_output.png")
A lo largo de los ejemplos, exploramos múltiples facetas de StableDiffusionControlNetPipeline para mostrar lo fácil e intuitivo que es jugar con ControlNet a través de los Difusores. Sin embargo, no cubrimos todos los tipos de condicionamientos soportados por ControlNet. Para saber más sobre ellos, te animamos a que consultes las respectivas páginas de documentación del modelo:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
- lllyasviel/sd-controlnet-canny
Te invitamos a combinar estos diferentes elementos y compartir tus resultados con @diffuserslib . Asegúrate de consultar el cuaderno de Colab para probar algunos de los ejemplos anteriores!
También mostramos algunas técnicas para hacer que el proceso de generación sea más rápido y que consuma menos memoria, utilizando un planificador rápido, la descarga inteligente del modelo y xformers . Con estas técnicas combinadas, el proceso de generación tarda solo ~3 segundos en una GPU V100 y consume solo ~4 GB de VRAM para una sola imagen ⚡️ En servicios gratuitos como Google Colab, la generación tarda aproximadamente 5 segundos en la GPU predeterminada (T4), mientras que la implementación original requiere 17 segundos para crear el mismo resultado! Combinar todas las piezas en la caja de herramientas de diffusers es un verdadero superpoder 💪
Conclusión
Hemos estado jugando mucho con StableDiffusionControlNetPipeline , ¡y nuestra experiencia ha sido divertida hasta ahora! Estamos emocionados de ver qué construye la comunidad sobre esta tubería. Si quieres ver otras tuberías y técnicas admitidas en Diffusers que permiten una generación controlada, consulta nuestra documentación oficial .
Si no puedes esperar para probar ControlNet directamente, ¡también te tenemos cubierto! Simplemente haz clic en uno de los siguientes espacios para jugar con ControlNet:
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Inferencia rápida en modelos de lenguaje grandes BLOOMZ en el acelerador Habana Gaudi2
- Boletín de Ética y Sociedad #3 Apertura Ética en Hugging Face
- StackLLaMA Una guía práctica para entrenar LLaMA con RLHF
- Acelerando Hugging Face Transformers con AWS Inferentia2
- Ejecutando IF con difusores 🧨 en un Google Colab de nivel gratuito
- Cómo instalar y usar la API de Unity de Hugging Face
- StarCoder Un LLM de última generación para el código





